Системы DLP: как это работает. Комплексные dlp-системы
Технология DLP
Digital Light Processing (DLP) — передовая технология, изобретенная компанией Texas Instruments . Благодаря ей оказалось возможным создавать очень небольшие, очень легкие (3 кг — разве это вес?) и, тем не менее, достаточно мощные (более 1000 ANSI Lm) мультимедиапроекторы.
Краткая история создания
Давным-давно, в далекой галактике…
В 1987 году Dr. Larry J. Hornbeck изобрел цифровое мультизеркальное устройство (Digital Micromirror Device или DMD). Это изобретение завершило десятилетние исследования Texas Instruments в области микромеханических деформируемых зеркальных устройств (Deformable Mirror Devices или снова DMD). Суть открытия состояла в отказе от гибких зеркал в пользу матрицы жестких зеркал, имеющих всего два устойчивых положения.
В 1989 году Texas Instruments становится одной из четырех компаний, избранных для реализации «проекторной» части программы U.S. High-Definition Display, финансируемой управлением перспективного планирования научно-исследовательских работ (ARPA).
В мае 1992 года TI демонстрирует первую основанную на DMD систему, поддерживающую современный стандарт разрешения для ARPA.
High-Definition TV (HDTV) версия DMD на основе трех DMD высокого разрешения была показана в феврале 1994 года.
Массовые продажи DMD-чипов началиcь в 1995 году.
Технология DLP
Ключевым элементом мультимедиапроекторов, созданных по технологии DLP, является матрица микроскопических зеркал (DMD-элементов) из алюминиевого сплава, обладающего очень высоким коэффициентом отражения. Каждое зеркало крепится к жесткой подложке, которая через подвижные пластины соединяется с основанием матрицы. Под противоположными углами зеркал размещены электроды, соединенные с ячейками памяти CMOS SRAM. Под действием электрического поля подложка с зеркалом принимает одно из двух положений, отличающихся точно на 20° благодаря ограничителям, расположенным на основании матрицы.
Два этих положения соответствуют отражению поступающего светового потока соответственно в объектив и эффективный светопоглотитель, обеспечивающий надежный отвод тепла и минимальное отражение света.
Шина данных и сама матрица сконструированы так, чтобы обеспечивать до 60 и более кадров изображения в секунду с разрешением 16 миллионов цветов.
Матрица зеркал вместе с CMOS SRAM и составляют DMD-кристалл — основу технологии DLP.
Впечатляют небольшие размеры кристалла. Площадь каждого зеркала матрицы составляет 16 микрон и менее, а расстояние между зеркалами около 1 микрона. Кристалл, да и не один, легко помещается на ладони.
Всего, если Texas Instruments нас не обманывает, выпускаются три вида кристаллов (или чипов) c различными разрешениями. Это:
- SVGA: 848×600; 508,800 зеркал
- XGA: 1024×768 с черной апертурой (межщелевым пространством); 786,432 зеркал
- SXGA: 1280×1024; 1,310,720 зеркал
 |
 |
Итак, у нас есть матрица, что мы можем с ней сделать? Ну конечно, осветить ее световым потоком помощнее и поместить на пути одного из направлений отражений зеркал оптическую систему, фокусирующую изображение на экран. На пути другого направления разумным будет поместить светопоглотитель, чтобы ненужный свет не причинял неудобств. Вот мы уже и можем проецировать одноцветные картинки. Но где же цвет? Где яркость?

А вот в этом, похоже, и заключалось изобретение товарища Larry, речь о котором шла в первом абзаце раздела истории создания DLP. Если вы так и не поняли, в чем дело, — приготовьтесь, ибо сейчас с вами может случиться шок:), т. к. это само собой напрашивающееся элегантное и вполне очевидное решение является на сегодня самым передовым и технологичным в области проецирования изображения.
Вспомните детский фокус с вращающимся фонариком, свет от которого в некоторый момент сливается и превращается в светящийся круг. Эта шутка нашего зрения и позволяет окончательно отказаться от аналоговых систем построения изображения в пользу полностью цифровых. Ведь даже цифровые мониторы на последнем этапе имеют аналоговую природу.
Но что произойдет, если мы заставим зеркало с большой частотой переключаться из одного положения в другое? Если пренебречь временем переключения зеркала (а благодаря его микроскопическим размерам этим временем вполне можно пренебречь), то видимая яркость упадет не иначе как в два раза. Изменяя отношение времени, в течение которого зеркало находится в одном и другом положении, мы легко можем изменять и видимую яркость изображения. А так как частота циклов очень и очень большая, никакого видимого мерцания не будет и в помине. Эврика. Хотя ничего особенного, это всё давно известно:)
Ну, а теперь последний штрих. Если скорость переключения достаточно высока, то на пути светового потока мы можем последовательно помещать светофильтры и тем самым создавать цветное изображение.
Вот, собственно, и вся технология. Дальнейшее ее эволюционное развитие мы проследим на примере устройства мультимедиапроекторов.
Устройство DLP-проекторов
Texas Instruments не занимается производством DLP-проекторов, этим занимается множество других компаний, таких, как 3M, ACER, PROXIMA, PLUS, ASK PROXIMA, OPTOMA CORP., DAVIS, LIESEGANG, INFOCUS, VIEWSONIC, SHARP, COMPAQ, NEC, KODAK, TOSHIBA, LIESEGANG и др. Большинство выпускаемых проекторов относятся к портативным, обладающим массой от 1,3 до 8 кг и мощностью до 2000 ANSI lumens. Проекторы делятся на три типа.
Одноматричный проектор
Самый простой тип, который мы уже описали, это — одноматричный проектор , где между источником света и матрицей помещается вращающийся диск с цветными светофильтрами — синим, зеленым и красным. Частота вращения диска определяет привычную нам частоту кадров.

Изображение формируется поочередно каждым из основных цветов, в результате получается обычное полноцветное изображение.
Все, или почти все портативные проекторы построены по одноматричному типу.
Дальнейшим развитием этого типа проекторов стало введение четвертого, прозрачного светофильтра, позволяющего ощутимо увеличить яркость изображения.
Трехматричный проектор
Самым сложным типом проекторов является трехматричный проектор , где свет расщепляется на три цветовых потока и отражается сразу от трех матриц. Такой проектор имеет самый чистый цвет и частоту кадров, не ограниченную скоростью вращения диска, как у одноматричных проекторов.

Точное соответствие отраженного потока от каждой матрицы (сведение) обеспечивается с помощью призмы, как вы можете видеть на рисунке.
Двухматричный проектор
Промежуточным типом проекторов является двухматричный проектор . В данном случае свет расщепляется на два потока: красный отражается от одной DMD-матрицы, а синий и зеленый — от другой. Светофильтр, соответственно, удаляет из спектра синюю либо зеленую составляющие поочередно.

Двухматричный проектор обеспечивает промежуточное качество изображения по сравнению с одноматричным и трехматричным типом.
Сравнение LCD и DLP-проекторов
По сравнению с LCD-проекторами DLP-проекторы обладают рядом важных преимуществ:

Есть ли недостатки у технологии DLP?
Но теория теорией, а на практике еще есть над чем поработать. Основной недостаток заключается в несовершенстве технологии и как следствие — проблеме залипания зеркал.
Дело в том, что при таких микроскопических размерах мелкие детали норовят «слипнуться», и зеркало с основанием тому не исключение.
Несмотря на приложенные компанией Texas Instruments усилия по изобретению новых материалов, уменьшающих прилипание микрозеркал, такая проблема существует, как мы увидели при тестировании мультимедиапроектора Infocus LP340 . Но, должен заметить, жить она особо не мешает.
Другая проблема не так очевидна и заключается в оптимальном подборе режимов переключения зеркал. У каждой компании, производящей DLP-проекторы, на этот счет свое мнение.
Ну и последнее. Несмотря на минимальное время переключения зеркал из одного положения в другое, едва заметный шлейф на экране этот процесс оставляет. Эдакий бесплатный antialiasing.
Развитие технологии
- Помимо введения прозрачного светофильтра постоянно ведутся работы по уменьшению межзеркального пространства и площади столбика, крепящего зеркало к подложке (черная точка посередине элемента изображения).
- Путем разбиения матрицы на отдельные блоки и расширения шины данных увеличивается частота переключения зеркал.
- Ведутся работы по увеличению количества зеркал и уменьшению размера матрицы.
- Постоянно повышается мощность и контрастность светового потока. В настоящее время уже существуют трехматричные проекторы мощностью свыше 10000 ANSI Lm и контрастностью более 1000:1, нашедшие свое применение в ультрасовременных кинотеатрах, использующих цифровые носители.
- Технология DLP полностью готова заменить CRT-технологию показа изображения в домашних кинотеатрах.
Заключение
Это далеко не все, что можно было бы рассказать о технологии DLP, например, мы не затронули тему использования DMD-матриц в печати. Но мы подождем, пока компания Texas Instruments не подтвердит информацию, доступную из других источников, дабы не подсунуть вам «липу». Надеюсь, этого небольшого рассказа вполне достаточно, чтобы получить пусть не самое полное, но достаточное представление о технологии и не мучать продавцов расспросами о преимуществе DLP-проекторов над другими.
Спасибо Алексею Слепынину за помощь в оформлении материала
Если быть достаточно последовательным в определениях, то можно сказать, что информационная безопасность началась именно с появления DLP-систем. До этого все продукты, которые занимались «информационной безопасностью», на самом деле защищали не информацию, а инфраструктуру - места хранения, передачи и обработки данных. Компьютер, приложение или канал, в которых находится, обрабатывается или передается конфиденциальная информация, защищаются этими продуктами точно так же, как и инфраструктура, в которой обращается совершенно безобидная информация. То есть именно с появлением DLP-продуктов информационные системы научились наконец-то отличать конфиденциальную информацию от неконфиденциальной. Возможно, с встраиванием DLP-технологий в информационную инфраструктуру компании смогут сильно сэкономить на защите информации - например, использовать шифрование только в тех случаях, когда хранится или передается конфиденциальная информация, и не шифровать информацию в других случаях.
Однако это дело будущего, а в настоящем данные технологии используются в основном для защиты информации от утечек. Технологии категоризации информации составляют ядро DLP-систем. Каждый производитель считает свои методы детектирования конфиденциальной информации уникальными, защищает их патентами и придумывает для них специальные торговые марки. Ведь остальные, отличные от этих технологий, элементы архитектуры (перехватчики протоколов, парсеры форматов, управление инцидентами и хранилища данных) у большинства производителей идентичны, а у крупных компаний даже интегрированы с другими продуктами безопасности информационной инфраструктуры. В основном для категоризации данных в продуктах по защите корпоративной информации от утечек используются две основных группы технологий - лингвистический (морфологический, семантический) анализ и статистические методы (Digital Fingerprints, Document DNA, антиплагиат). Каждая технология имеет свои сильные и слабые стороны, которые определяют область их применения.
Лингвистический анализ
Использование стоп-слов («секретно», «конфиденциально» и тому подобных) для блокировки исходящих электронных сообщений в почтовых серверах можно считать прародителем современных DLPсистем. Конечно, от злоумышленников это не защищает - удалить стоп-слово, чаще всего вынесенное в отдельный гриф документа, не составляет труда, при этом смысл текста нисколько не изменится.
Толчок в разработке лингвистических технологий был сделан в начале этого века создателями email-фильтров. Прежде всего, для защиты электронной почты от спама. Это сейчас в антиспамовских технологиях преобладают репутационные методы, а в начале века шла настоящая лингвистическая война между снарядом и броней - спамерами и антиспамерами. Помните простейшие методы для обмана фильтров, базирующихся на стоп-словах? Замена букв на похожие буквы из других кодировок или цифры, транслит, случайным образом расставленные пробелы, подчеркивания или переходы строк в тексте. Антиспамеры довольно быстро научились бороться с такими хитростями, но тогда появился графический спам и прочие хитрые разновидности нежелательной корреспонденции.
Однако использовать антиспамерские технологии в DLP-продуктах без серьезной доработки невозможно. Ведь для борьбы со спамом достаточно делить информационный поток на две категории: спам и не спам. Метод Байеса, который используется при детектировании спама, дает только бинарный результат: «да» или «нет». Для защиты корпоративных данных от утечек этого недостаточно - нельзя просто делить информацию на конфиденциальную и неконфиденциальную. Нужно уметь классифицировать информацию по функциональной принадлежности (финансовая, производственная, технологическая, коммерческая, маркетинговая), а внутри классов - категоризировать ее по уровню доступа (для свободного распространения, для ограниченного доступа, для служебного использования, секретная, совершенно секретная и так далее).
Большинство современных систем лингвистического анализа используют не только контекстный анализ (то есть в каком контексте, в сочетании с какими другими словами используется конкретный термин), но и семантический анализ текста. Эти технологии работают тем эффективнее, чем больше анализируемый фрагмент. На большом фрагменте текста точнее проводится анализ, с большей вероятностью определяется категория и класс документа. При анализе же коротких сообщений (SMS, интернет-пейджеры) ничего лучшего, чем стоп-слова, до сих пор не придумано. Автор столкнулся с такой задачей осенью 2008 года, когда с рабочих мест многих банков через мессенджеры пошли в Сеть тысячи сообщений типа «нас сокращают», «отберут лицензию», «отток вкладчиков», которые нужно было немедленно заблокировать у своих клиентов.
Достоинства технологии
Достоинства лингвистических технологий в том, что они работают напрямую с содержанием документов, то есть им не важно, где и как был создан документ, какой на нем гриф и как называется файл - документы защищаются немедленно. Это важно, например, при обработке черновиков конфиденциальных документов или для защиты входящей документации. Если документы, созданные и использующиеся внутри компании, еще как-то можно специфическим образом именовать, грифовать или метить, то входящие документы могут иметь не принятые в организации грифы и метки. Черновики (если они, конечно, не создаются в системе защищенного документооборота) тоже могут уже содержать конфиденциальную информацию, но еще не содержать необходимых грифов и меток.
Еще одно достоинство лингвистических технологий - их обучаемость. Если ты хоть раз в жизни нажимал в почтовом клиенте кнопку «Не спам», то уже представляешь клиентскую часть системы обучения лингвистического движка. Замечу, что тебе совершенно не нужно быть дипломированным лингвистом и знать, что именно изменится в базе категорий - достаточно указать системе ложное срабатывание, все остальное она сделает сама.
Третьим достоинством лингвистических технологий является их масштабируемость. Скорость обработки информации пропорциональна ее количеству и абсолютно не зависит от количества категорий. До недавнего времени построение иерархической базы категорий (исторически ее называют БКФ - база контентной фильтрации, но это название уже не отражает настоящего смысла) выглядело неким шаманством профессиональных лингвистов, поэтому настройку БКФ можно было смело отнести к недостаткам. Но с выходом в 2010 сразу нескольких продуктов-«автолингвистов» построение первичной базы категорий стало предельно простым - системе указываются места, где хранятся документы определенной категории, и она сама определяет лингвистические признаки этой категории, а при ложных срабатываниях - самостоятельно обучается. Так что теперь к достоинствам лингвистических технологий добавилась простота настройки.
И еще одно достоинство лингвистических технологий, которое хочется отметить в статье - возможность детектировать в информационных потоках категории, не связанные с документами, находящимися внутри компании. Инструмент для контроля содержимого информационных потоков может определять такие категории, как противоправная деятельность (пиратство, распространение запрещенных товаров), использование инфраструктуры компании в собственных целях, нанесение вреда имиджу компании (например, распространение порочащих слухов) и так далее.
Недостатки технологий
Основным недостатком лингвистических технологий является их зависимость от языка. Невозможно использовать лингвистический движок, разработанный для одного языка, в целях анализа другого. Это было особенно заметно при выходе на российский рынок американских производителей - они были не готовы столкнуться с российским словообразованием и наличием шести кодировок. Недостаточно было перевести на русский язык категории и ключевые слова - в английском языке словообразование довольно простое, а падежи выносятся в предлоги, то есть при изменении падежа меняется предлог, а не само слово. Большинство существительных в английском языке становятся глаголами без изменений слова. И так далее. В русском все не так - один корень может породить десятки слов в разных частях речи.
В Германии американских производителей лингвистических технологий встретила другая проблема - так называемые «компаунды», составные слова. В немецком языке принято присоединять определения к главному слову, в результате чего получаются слова, иногда состоящие из десятка корней. В английском языке такого нет, там слово - последовательность букв между двумя пробелами, соответственно английский лингвистический движок оказался неспособен обработать незнакомые длинные слова.
Справедливости ради следует сказать, что сейчас эти проблемы во многом американскими производителями решены. Пришлось довольно сильно переделать (а иногда и писать заново) языковой движок, но большие рынки России и Германии наверняка того стоят. Также сложно обрабатывать лингвистическими технологиями мультиязычные тексты. Однако с двумя языками большинство движков все-таки справляются, обычно это национальный язык + английский - для большинства бизнес-задач этого вполне достаточно. Хотя автору встречались конфиденциальные тексты, содержащие, например, одновременно казахский, русский и английский, но это скорее исключение, чем правило.
Еще одним недостатком лингвистических технологий для контроля всего спектра корпоративной конфиденциальной информации является то, что не вся конфиденциальная информация находится в виде связных текстов. Хотя в базах данных информация и хранится в текстовом виде, и нет никаких проблем извлечь текст из СУБД, полученная информация чаще всего содержит имена собственные - ФИО, адреса, названия компаний, а также цифровую информацию - номера счетов, кредитных карт, их баланс и прочее. Обработка подобных данных с помощью лингвистики много пользы не принесет. То же самое можно сказать о форматах CAD/CAM, то есть чертежах, в которых зачастую содержится интеллектуальная собственность, программных кодах и медийных (видео/аудио) форматах - какие-то тексты из них можно извлечь, но их обработка также неэффективна. Еще года три назад это касалось и отсканированных текстов, но лидирующие производители DLP-систем оперативно добавили оптическое распознавание и справились с этой проблемой.
Но самым большим и наиболее часто критикуемым недостатком лингвистических технологий является все-таки вероятностный подход к категоризации. Если ты когда-нибудь читал письмо с категорией «Probably SPAM», то поймешь, о чем я. Если такое творится со спамом, где всего две категории (спам/не спам), можно себе представить, что будет, когда в систему загрузят несколько десятков категорий и классов конфиденциальности. Хотя обучением системы можно достигнуть 92-95% точности, для большинства пользователей это означает, что каждое десятое или двадцатое перемещение информации будет ошибочно причислено не к тому классу со всеми вытекающими для бизнеса последствиями (утечка или прерывание легитимного процесса).
Обычно не принято относить к недостаткам сложность разработки технологии, но не упомянуть о ней нельзя. Разработка серьезного лингвистического движка с категоризацией текстов более чем по двум категориям - наукоемкий и довольно сложный технологически процесс. Прикладная лингвистика - быстро развивающаяся наука, получившая сильный толчок в развитии с распространением интернет-поиска, но сегодня на рынке присутствуют единицы работоспособных движков категоризации: для русского языка их всего два, а для некоторых языков их просто еще не разработали. Поэтому на DLP-рынке существует лишь пара компаний, которые способны в полной мере категоризировать информацию «на лету». Можно предположить, что когда рынок DLP увеличится до многомиллиардных размеров, на него с легкостью выйдет Google. С собственным лингвистическим движком, оттестированным на триллионах поисковых запросов по тысячам категорий, ему не составит труда сразу отхватить серьезный кусок этого рынка.
Статистические методы
Задача компьютерного поиска значимых цитат (почему именно «значимых» - немного позже) заинтересовала лингвистов еще в 70-х годах прошлого века, если не раньше. Текст разбивался на куски определенного размера, с каждого из которых снимался хеш. Если некоторая последовательность хешей встречалась в двух текстах одновременно, то с большой вероятностью тексты в этих областях совпадали.
Побочным продуктом исследований в этой области является, например, «альтернативная хронология» Анатолия Фоменко, уважаемого ученого, который занимался «корреляциями текстов» и однажды сравнил русские летописи разных исторических периодов. Удивившись, насколько совпадают летописи разных веков (более чем на 60%), в конце 70-х он выдвинул теорию, что наша хронология на несколько веков короче. Поэтому, когда какая-то выходящая на рынок DLP-компания предлагает «революционную технологию поиска цитат», можно с большой вероятностью утверждать, что ничего, кроме новой торговой марки, компания не создала.
Статистические технологии относятся к текстам не как к связной последовательности слов, а как к произвольной последовательности символов, поэтому одинаково хорошо работают с текстами на любых языках. Поскольку любой цифровой объект - хоть картинка, хоть программа - тоже последовательность символов, то те же методы могут применяться для анализа не только текстовой информации, но и любых цифровых объектов. И если совпадают хеши в двух аудиофайлах - наверняка в одном из них содержится цитата из другого, поэтому статистические методы являются эффективными средствами защиты от утечки аудио и видео, активно применяющиеся в музыкальных студиях и кинокомпаниях.
Самое время вернуться к понятию «значимая цитата». Ключевой характеристикой сложного хеша, снимаемого с защищаемого объекта (который в разных продуктах называется то Digital Fingerprint, то Document DNA), является шаг, с которым снимается хеш. Как можно понять из описания, такой «отпечаток» является уникальной характеристикой объекта и при этом имеет свой размер. Это важно, поскольку если снять отпечатки с миллионов документов (а это объем хранилища среднего банка), то для хранения всех отпечатков понадобится достаточное количество дискового пространства. От шага хеша зависит размер такого отпечатка - чем меньше шаг, тем больше отпечаток. Если снимать хеш с шагом в один символ, то размер отпечатка превысит размер самого образца. Если для уменьшения «веса» отпечатка увеличить шаг (например, 10 000 символов), то вместе с этим увеличивается вероятность того, что документ, содержащий цитату из образца длиной в 9 900 символов, будет конфиденциальным, но при этом проскочит незаметно.
С другой стороны, если для увеличения точности детекта брать очень мелкий шаг, несколько символов, то можно увеличить количество ложных срабатываний до неприемлемой величины. В терминах текста это означает, что не стоит снимать хеш с каждой буквы - все слова состоят из букв, и система будет принимать наличие букв в тексте за содержание цитаты из текста-образца. Обычно производители сами рекомендуют некоторый оптимальный шаг снятия хешей, чтобы размер цитаты был достаточный и при этом вес самого отпечатка был небольшой - от 3% (текст) до 15% (сжатое видео). В некоторых продуктах производители позволяют менять размер значимости цитаты, то есть увеличивать или уменьшать шаг хеша.
Достоинства технологии
Как можно понять из описания, для детектирования цитаты нужен объект-образец. И статистические методы могут с хорошей точностью (до 100%) сказать, есть в проверяемом файле значимая цитата из образца или нет. То есть система не берет на себя ответственность за категоризацию документов - такая работа полностью лежит на совести того, кто категоризировал файлы перед снятием отпечатков. Это сильно облегчает защиту информации в случае, если на предприятии в некотором месте (местах) хранятся нечасто изменяющиеся и уже категоризированные файлы. Тогда достаточно с каждого из этих файлов снять отпечаток, и система будет, в соответствии с настройками, блокировать пересылку или копирование файлов, содержащих значимые цитаты из образцов.
Независимость статистических методов от языка текста и нетекстовой информации - тоже неоспоримое преимущество. Они хороши при защите статических цифровых объектов любого типа - картинок, аудио/видео, баз данных. Про защиту динамических объектов я расскажу в разделе «недостатки».
Недостатки технологии
Как и в случае с лингвистикой, недостатки технологии - обратная сторона достоинств. Простота обучения системы (указал системе файл, и он уже защищен) перекладывает на пользователя ответственность за обучение системы. Если вдруг конфиденциальный файл оказался не в том месте либо не был проиндексирован по халатности или злому умыслу, то система его защищать не будет. Соответственно, компании, заботящиеся о защите конфиденциальной информации от утечки, должны предусмотреть процедуру контроля того, как индексируются DLP-системой конфиденциальные файлы.
Еще один недостаток - физический размер отпечатка. Автор неоднократно видел впечатляющие пилотные проекты на отпечатках, когда DLP-система со 100% вероятностью блокирует пересылку документов, содержащих значимые цитаты из трехсот документов-образцов. Однако через год эксплуатации системы в боевом режиме отпечаток каждого исходящего письма сравнивается уже не с тремя сотнями, а с миллионами отпечатков-образцов, что существенно замедляет работу почтовой системы, вызывая задержки в десятки минут.
Как я и обещал выше, опишу свой опыт по защите динамических объектов с помощью статистических методов. Время снятия отпечатка напрямую зависит от размера файла и его формата. Для текстового документа типа этой статьи это занимает доли секунды, для полуторачасового MP4-фильма - десятки секунд. Для редкоизменяемых файлов это не критично, но если объект меняется каждую минуту или даже секунду, то возникает проблема: после каждого изменения объекта с него нужно снять новый отпечаток… Код, над которым работает программист, еще не самая большая сложность, гораздо хуже с базами данных, используемыми в биллинге, АБС или call-центрах. Если время снятия отпечатка больше, чем время неизменности объекта, то задача решения не имеет. Это не такой уж и экзотический случай - например, отпечаток базы данных, хранящей номера телефонов клиентов федерального сотового оператора, снимается несколько дней, а меняется ежесекундно. Поэтому, когда DLP-вендор утверждает, что его продукт может защитить вашу базу данных, мысленно добавляйте слово «квазистатическую».
Единство и борьба противоположностей
Как видно из предыдущего раздела статьи, сила одной технологии проявляется там, где слаба другая. Лингвистике не нужны образцы, она категоризирует данные на лету и может защищать информацию, с которой случайно или умышленно не был снят отпечаток. Отпечаток дает лучшую точность и поэтому предпочтительнее для использования в автоматическом режиме. Лингвистика отлично работает с текстами, отпечатки - с другими форматами хранения информации.
Поэтому большинство компаний-лидеров используют в своих разработках обе технологии, при этом одна из них является основной, а другая - дополнительной. Это связано с тем, что изначально продукты компании использовали только одну технологию, в которой компания продвинулась дальше, а затем, по требованию рынка, была подключена вторая. Так, например, ранее InfoWatch использовал только лицензированную лингвистическую технологию Morph-OLogic, а Websense - технологию PreciseID, относящуюся к категории Digital Fingerprint, но сейчас компании используют оба метода. В идеале использовать две эти технологии нужно не параллельно, а последовательно. Например, отпечатки лучше справятся с определением типа документа - договор это или балансовая ведомость, например. Затем можно подключать уже лингвистическую базу, созданную специально для этой категории. Это сильно экономит вычислительные ресурсы.
За пределами статьи остались еще несколько типов технологий, используемых в DLP-продуктах. К таким относятся, например, анализатор структур, позволяющий находить в объектах формальные структуры (номера кредитных карт, паспортов, ИНН и так далее), которые невозможно детектировать ни с помощью лингвистики, ни с помощью отпечатков. Также не раскрыта тема разного типа меток - от записей в атрибутных полях файла или просто специального наименования файлов до специальных криптоконтейнеров. Последняя технология отживает свое, поскольку большинство производителей предпочитает не изобретать велосипед самостоятельно, а интегрироваться с производителями DRM-систем, такими как Oracle IRM или Microsoft RMS.
DLP-продукты - быстроразвивающаяся отрасль информационной безопасности, у некоторых производителей новые версии выходят очень часто, более одного раза в год. С нетерпением ждем появления новых технологий анализа корпоративного информационного поля для увеличения эффективности защиты конфиденциальной информации.
В наши дни можно часто услышать о такой технологии, как DLP-системы. Что это такое, и где это используется? Это программное обеспечение, предназначенное для предотвращения потери данных путем обнаружения возможных нарушений при их отправке и фильтрации. Кроме того, такие сервисы осуществляют мониторинг, обнаружение и блокирование при ее использовании, движении (сетевом трафике), а также хранении.
Как правило, утечка конфиденциальных данных происходит по причине работы с техникой неопытных пользователей либо является результатом злонамеренных действий. Такая информация в виде частных или корпоративных сведений, объектов интеллектуальной собственности (ИС), финансовой или медицинской информации, сведений кредитных карт и тому подобное нуждается в усиленных мерах защиты, которые могут предложить современные информационные технологии.
Термины «потеря данных» и «утечка данных» связаны между собой и часто используются как синонимы, хотя они несколько отличаются. Случаи утери информации превращаются в ее утечку тогда, когда источник, содержащий конфиденциальные сведения, пропадает и впоследствии оказывается у несанкционированной стороны. Тем не менее утечка данных возможна без их потери.
Категории DLP
Технологические средства, используемые для борьбы с утечкой данных, можно разделить на следующие категории: стандартные меры безопасности, интеллектуальные (продвинутые) меры, контроль доступа и шифрование, а также специализированные DLP-системы (что это такое - подробно описано ниже).

Стандартные меры
Такие стандартные меры безопасности, как системы обнаружения вторжений (IDS) и антивирусное программное обеспечение, представляют собой обычные доступные механизмы, которые охраняют компьютеры от аутсайдера, а также инсайдерских атак. Подключение брандмауэра, к примеру, исключает доступ к внутренней сети посторонних лиц, а система обнаружения вторжений обнаруживает попытки проникновения. Внутренние атаки возможно предотвратить путем проверки антивирусом, обнаруживающих установленных на ПК, которые отправляют конфиденциальную информацию, а также за счет использования сервисов, которые работают в архитектуре клиент-сервер без каких-либо личных или конфиденциальных данных, хранящихся на компьютере.
Дополнительные меры безопасности
Дополнительные меры безопасности используют узкоспециализированные сервисы и временные алгоритмы для обнаружения ненормального доступа к данным (т. е. к базам данных либо информационно-поисковых системам) или ненормального обмена электронной почтой. Кроме того, такие современные информационные технологии выявляют программы и запросы, поступающие с вредоносными намерениями, и осуществляют глубокие проверки компьютерных систем (например, распознавание нажатий клавиш или звуков динамика). Некоторые такие сервисы способны даже проводить мониторинг активности пользователей для обнаружения необычного доступа к данным.

Специально разработанные DLP-системы - что это такое?
Разработанные для защиты информации DLP-решения служат для обнаружения и предотвращения несанкционированных попыток копировать или передавать конфиденциальные данные (преднамеренно или непреднамеренно) без разрешения или доступа, как правило, со стороны пользователей, которые имеют право доступа к конфиденциальным данным.
Для того чтобы классифицировать определенную информацию и регулировать доступ к ней, эти системы используют такие механизмы, как точное соответствие данных, структурированная дактилоскопия, прием правил и регулярных выражений, опубликований кодовых фраз, концептуальных определений и ключевых слов. Типы и сравнение DLP-систем можно представить следующим образом.
Network DLP (также известная как анализ данных в движении или DiM)
Как правило, она представляет собой аппаратное решение либо программное обеспечение, которое устанавливается в точках сети, исходящих вблизи периметра. Она анализирует сетевой трафик для обнаружения конфиденциальных данных, отправляемых в нарушение

Endpoint DLP (данные при использовании )
Такие системы функционируют на рабочих станциях конечных пользователей или серверов в различных организациях.
Как и в других сетевых системах, конечная точка может быть обращена как к внутренним, так и к внешним связям и, следовательно, может быть использована для контроля потока информации между типами либо группами пользователей (например, «файерволы»). Они также способны осуществлять контроль за электронной почтой и обменом мгновенными сообщениями. Это происходит следующим образом - прежде, чем сообщения будут загружены на устройство, они проверяются сервисом, и при содержании в них неблагоприятного запроса они блокируются. В результате они становятся неоправленными и не подпадают под действие правил хранения данных на устройстве.
DLP-система (технология) имеет преимущество в том, что она может контролировать и управлять доступом к устройствам физического типа (к примеру, мобильные устройства с возможностями хранения данных), а также иногда получать доступ к информации до ее шифрования.

Некоторые системы, функционирующие на основе конечных точек, также могут обеспечить контроль приложений, чтобы блокировать попытки передачи конфиденциальной информации, а также обеспечить незамедлительную обратную связь с пользователем. Вместе с тем они имеют недостаток в том, что они должны быть установлены на каждой рабочей станции в сети, и не могут быть использованы на мобильных устройствах (например, на сотовых телефонах и КПК) или там, где они не могут быть практически установлены (например, на рабочей станции в интернет-кафе). Это обстоятельство необходимо учитывать, делая выбор DLP-системы для каких-либо целей.
Идентификация данных
DLP-системы включают в себя несколько методов, направленных на выявление секретной либо конфиденциальной информации. Иногда этот процесс путают с расшифровкой. Однако идентификация данных представляет собой процесс, посредством которого организации используют технологию DLP, чтобы определить, что искать (в движении, в состоянии покоя или в использовании).
Данные при этом классифицируются как структурированные или неструктурированные. Первый тип хранится в фиксированных полях внутри файла (например, в виде электронных таблиц), в то время как неструктурированный относится к свободной форме текста (в форме текстовых документов или PDF-файлов).
По оценкам специалистов, 80% всех данных - неструктурированные. Соответственно, 20% - структурированные. основывается на контент-анализе, ориентированном на структурированную информацию и контекстный анализ. Он делается по месту создания приложения или системы, в которой возникли данные. Таким образом, ответом на вопрос «DLP-системы - что это такое?» послужит определение алгоритма анализа информации.
Используемые методы
Методы описания конфиденциального содержимого на сегодняшний день многочисленны. Их можно разделить на две категории: точные и неточные.
Точные методы - это те, которые связаны с анализом контента и практически сводят к нулю ложные положительные ответы на запросы.
Все остальные являются неточными и могут включать в себя: словари, ключевые слова, регулярные выражения, расширенные регулярные выражения, мета-теги данных, байесовский анализ, статистический анализ и т. д.

Эффективность анализа напрямую зависит от его точности. DLP-система, рейтинг которой высок, имеет высокие показатели по данному параметру. Точность идентификации DLP имеет важное значение для избегания ложных срабатываний и негативных последствий. Точность может зависеть от многих факторов, некоторые из которых могут быть ситуативными или технологическими. Тестирование точности может обеспечить надежность работы DLP-системы - практически нулевое количество ложных срабатываний.
Обнаружение и предотвращение утечек информации
Иногда источник распределения данных делает конфиденциальную информацию доступной для третьих лиц. Через некоторое время часть ее, вероятнее всего, обнаружится в несанкционированном месте (например, в интернете или на ноутбуке другого пользователя). DLP-системы, цена которых предоставляется разработчиками по запросу и может составлять от нескольких десятков до нескольких тысяч рублей, должны затем исследовать, как просочились данные - от одного или нескольких третьих лиц, было ли это независимо друг от друга, не обеспечивалась ли утечка какими-то другими средствами и т. д.
Данные в покое
«Данные в состоянии покоя» относятся к старой архивной информации, хранящейся на любом из жестких дисков клиентского ПК, на удаленном файловом сервере, на диске Также это определение относится к данным, хранящимся в системе резервного копирования (на флешках или компакт-дисках). Эти сведения представляют большой интерес для предприятий и государственных учреждений просто потому, что большой объем данных содержится неиспользованным в устройствах памяти, и более вероятно, что доступ к ним может быть получен неуполномоченными лицами за пределами сети.
D LP-систему используют, когда необходимо обеспечить защиту конфиденциальных данных от внутренних угроз. И если специалисты по информационной безопасности в достаточной мере освоили и применяют инструменты защиты от внешних нарушителей, то с внутренними дело обстоит не так гладко.
Использование в структуре информационной безопасности DLP-системы предполагает, что ИБ-специалист понимает:
- как сотрудники компании могут организовать утечку конфиденциальных данных;
- какую информацию следует защищать от угрозы нарушения конфиденциальности.
Всесторонние знания помогут специалисту лучше понять принципы работы технологии DLP и настроить защиту от утечек корректным образом.
DLP-система должна уметь отличать конфиденциальную информацию от неконфиденциальной. Если анализировать все данные внутри информационной системы организации, возникает проблема избыточной нагрузки на IT-ресурсы и персонал. DLP работает в основном «в связке» с ответственным специалистом, который не только «учит» систему корректно работать, вносит новые и удаляет неактуальные правила, но и проводит мониторинг текущих, заблокированных или подозрительных событий в информационной системе.
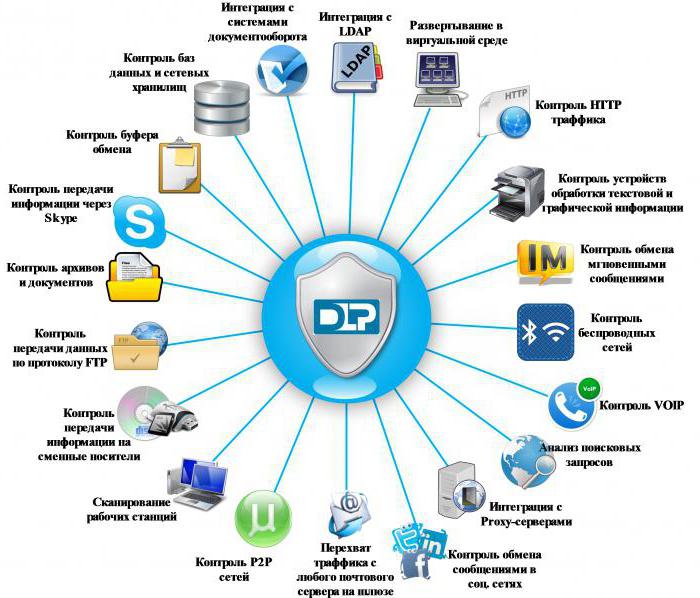
Функциональность DLP-системы строится вокруг «ядра» - программного алгоритма, который отвечает за обнаружение и категоризацию информации, нуждающейся в защите от утечек. В ядре большинства DLP-решений заложены две технологии: лингвистического анализа и технология, основанная на статистических методах. Также в ядре могут использоваться менее распространенные техники, например, применение меток или формальные методы анализа.
Разработчики систем противодействия утечкам дополняют уникальный программный алгоритм системными агентами, механизмами управления инцидентами, парсерами, анализаторами протоколов, перехватчиками и другими инструментами.
Ранние DLP-системы базировались на одном методе в ядре: либо лингвистическом, либо статистическом анализе. На практике недостатки двух технологий компенсировались сильными сторонами друг друга, и эволюция DLP привела к созданию систем, универсальных в плане «ядра».
Лингвистический метод анализа работает напрямую с содержанием файла и документа. Это позволяет игнорировать такие параметры, как имя файла, наличие либо отсутствие в документе грифа, кто и когда создал документа. Технология лингвистической аналитики включает:
- морфологический анализ - поиск по всем возможным словоформам информации, которую необходимо защитить от утечки;
- семантический анализ - поиск вхождений важной (ключевой) информации в содержимом файла, влияние вхождений на качественные характеристики файла, оценка контекста использования.
Лингвистический анализ показывает высокое качество работы с большим объемом информации. Для объемного текста DLP-система с алгоритмом лингвистического анализа более точно выберет корректный класс, отнесет к нужной категории и запустит настроенное правило. Для документов небольшого объема лучше использовать методику стоп-слов, которая эффективно зарекомендовала себя в борьбе со спамом.
Обучаемость в системах с лингвистическим алгоритмом анализа реализована на высоком уровне. У ранних DLP-комплексов были сложности с заданием категорий и другими этапами «обучения», однако в современных системах заложены отлаженные алгоритмы самообучения: выявления признаков категорий, возможности самостоятельно формировать и изменять правила реагирования. Для настройки в информационных системах подобных программных комплексов защиты данных уже не требуется привлекать лингвистов.
К недостаткам лингвистического анализа причисляют привязку к конкретному языку, когда нельзя использовать DLP-систему с «английским» ядром для анализа русскоязычных потоков информации и наоборот. Другой недостаток связан со сложностью четкой категоризации с использованием вероятностного подхода, что удерживает точность срабатывания в пределах 95%, тогда как для компании критичной может оказаться утечка любого объема конфиденциальной информации.
Статистические методы анализа , напротив, демонстрируют точность, близкую к 100-процентной. Недостаток статистического ядра связан с алгоритмом самого анализа.
На первом этапе документ (текст) делится на фрагменты приемлемой величины (не посимвольно, но достаточно, чтобы обеспечить точность срабатывания). С фрагментов снимается хеш (в DLP-системах встречается как термин Digital Fingerprint - «цифровой отпечаток»). Затем хеш сравнивается с хешем эталонного фрагмента, взятого из документа. При совпадении система помечает документ как конфиденциальный и действует в соответствии с политиками безопасности.
Недостаток статистического метода в том, что алгоритм не способен самостоятельно обучаться, формировать категории и типизировать. Как следствие - зависимость от компетенций специалиста и вероятность задания хеша такого размера, при котором анализ будет давать избыточное количество ложных срабатываний. Устранить недостаток несложно, если придерживаться рекомендаций разработчика по настройке системы.
С формированием хешей связан и другой недостаток. В развитых IT-системах, которые генерируют большие объемы данных, база отпечатков может достигать такого размера, что проверка трафика на совпадения с эталоном серьезно замедлит работу всей информационной системы.
Преимущество решений заключается в том, что результативность статистического анализа не зависит от языка и наличия в документе нетекстовой информации. Хеш одинаково хорошо снимается и с английской фразы, и с изображения, и с видеофрагмента.
Лингвистические и статистические методы не подходят для обнаружения данных определенного формата для любого документа, например, номера счетов или паспорта. Для выявления в массиве информации подобных типовых структур в ядро DLP-системы внедряют технологии анализа формальных структур.
В качественном DLP-решении используются все средства анализа, которые работают последовательно, дополняя друг друга.
Определить, какие технологии присутствуют в ядре, можно .
Не меньшее значение, чем функциональность ядра, имеют уровни контроля, на которых работает DLP-система. Их два:
Разработчики современных DLP-продуктов отказались от обособленной реализации защиты уровней, поскольку от утечки нужно защищать и конечные устройства, и сеть.
Сетевой уровень контроля при этом должен обеспечивать максимально возможный охват сетевых протоколов и сервисов. Речь идет не только о «традиционных» каналах ( , FTP, ), но и о более новых системах сетевого обмена (Instant Messengers, ). К сожалению, на сетевом уровне невозможно контролировать шифрованный трафик, но данная проблема в DLP-системах решена на уровне хоста.
Контроль на хостовом уровне позволяет решать больше задач по мониторингу и анализу. Фактически ИБ-служба получает инструмент полного контроля за действиями пользователя на рабочей станции. DLP с хостовой архитектурой позволяет отслеживать, что , какие документы , что набирается на клавиатуре, записывать аудиоматериалы, делать . На уровне конечной рабочей станции перехватывается шифрованный трафик (), а для проверки открыты данные, которые обрабатываются в текущий момент и которые длительное время хранятся на ПК пользователя.
Помимо решения обычных задач, DLP-системы с контролем на хостовом уровне обеспечивают дополнительные меры по обеспечению информационной безопасности: контроль установки и изменения ПО, блокировка портов ввода-вывода и т.п.
Минусы хостовой реализации в том, что системы с обширным набором функций сложнее администрировать, они более требовательны к ресурсам самой рабочей станции. Управляющий сервер регулярно обращается к модулю-«агенту» на конечном устройстве, чтобы проверить доступность и актуальность настроек. Кроме того, часть ресурсов пользовательской рабочей станции будет неизбежно «съедаться» модулем DLP. Поэтому еще на этапе подбора решения для предотвращения утечки важно обратить внимание на аппаратные требования.
Принцип разделения технологий в DLP-системах остался в прошлом. Современные программные решения для предотвращения утечек задействуют методы, которые компенсируют недостатки друг друга. Благодаря комплексному подходу конфиденциальные данные внутри периметра информационной безопасности становится более устойчивыми к угрозам.
Проблематика предотвращения утечек конфиденциальных данных (Data Loss Prevention, DLP) — одна из наиболее актуальных сегодня для ИТ. Тем не менее в этой сфере существует заметная понятийная путаница, которая усугубляется появлением множества похожих терминов, в частности, Data Leak Prevention (DLP), Information Leak Prevention (ILP), Information Leak Protection (ILP), Information Leak Detection & Prevention (ILDP), Content Monitoring and Filtering (CMF), Extrusion Prevention System (EPS).
Из каких функциональных модулей должно состоять полноценное DLP-решение? Где следует устанавливать DLP-системы: на уровне шлюзов передачи данных или на конечных информационных ресурсах (ПК или мобильных устройствах)? Имеет ли значение, как внедряется система DLP: как самостоятельное решение или как часть более широкой гаммы продуктов безопасности? Чтобы ответить на эти и другие вопросы, прежде всего нужно понять, что такое система DLP, из чего она состоит и как работает.
Для начала отметим, что конфиденциальная информация - это информация, доступ к которой ограничивается в соответствии с законодательством страны и уровнем доступа к информационному ресурсу. Конфиденциальная информация становится доступной или раскрытой только санкционированным лицам, объектам или процессам.
Существует четкий подход к классификации видов конфиденциальной информации:
- данные клиентов - такие персональные данные, как номера кредитных карт, паспортов, страховок, ИНН, водительских удостоверений и т. д.;
- корпоративные данные - финансовые данные, данные о слияниях и поглощениях, персональные данные сотрудников и т. д.;
- интеллектуальная собственность - исходные коды, конструкторская документация, информация о ценах и т. д.
Исходя из этого, можно сказать, что система предотвращения утечек конфиденциальной информации - это интегрированный набор инструментов для предотвращения или контроля перемещения конфиденциальной информации из информационной системы компании вовне.
Современные DLP-системы основаны на анализе потоков данных, пересекающих периметр защищаемой информационной системы. При выявлении в потоке конфиденциальной информации срабатывает защита, и передача сообщения (пакета, потока, сессии) блокируется или отслеживается.
Помимо основной своей функции DLP-решения помогают ответить на три простых, но очень важных вопроса: «Где находится моя конфиденциальная информация?», «Как используются эти данные?» и «Как лучше всего защитить их от потери?». Чтобы ответить на них, DLP-система выполняет глубокий анализ содержания информации, организует автоматическую защиту конфиденциальных данных в конечных информационных ресурсах, на уровне шлюзов передачи данных и в системах статического хранения данных, а также запускает процедуры реагирования на инциденты для принятия надлежащих мер.
Рассмотрим функционал DLP-решения на примере программного продукта компании Symantec - DLP 9.0 (Vontu DLP), который представляет собой интегрированный и централизованно управляемый комплекс средств мониторинга и предотвращения утечки конфиденциальных данных из защищаемого информационного контура. Он включает следующие основные компоненты DLP.
Endpoint DLP - модуль контроля перемещения информации на ПК и ноутбуках. Позволяет в режиме реального времени отслеживать, а в случае обнаружения запрещенного контента - и блокировать попытки копирования информации на съемные носители информации, печать и отсылку по факсу, по электронной почте и т. д. Контроль осуществляется как при подключении ПК к корпоративной сети, так и в автономном режиме или при удаленной работе. Помимо бесшумного контроля и предотвращения утечек система может информировать пользователя о неправомерности его действий, что позволяет обучать персонал правилам работы с конфиденциальной информацией.
Storage DLP - модуль контроля соблюдения процедур хранения конфиденциальных данных. Позволяет в режиме сканирования по расписанию обнаруживать статически хранимые конфиденциальные данные на файловых, почтовых, Web-серверах, в системах документооборота, на серверах баз данных и т. д. Проводит анализ легитимности хранения данных в их текущем местонахождении и перенос при необходимости в защищенные хранилища.
Network DLP - модуль контроля перемещения информации через шлюзы передачи данных. Позволяет отслеживать передачу информации по любому каналу TCP/IP или UDP. Система контролирует обмен информацией через IM и пиринговые системы, а также позволяет блокировать пересылку информации через HTTP(s), FTP(s) и SMTP-каналы с возможностью информирования пользователей о нарушении корпоративной политики.
Enforce Platform - система централизованного управления всеми модулями системы. Она позволяет управлять работоспособностью самой системы, отслеживая ее производительность и нагрузку, и администрировать правила и политики с точки зрения контроля за перемещением конфиденциальных данных. Система полностью основана на Web-технологиях и содержит весь инструментарий для организации полного жизненного цикла процесса управления политиками безопасности обращения с конфиденциальными данными в компании, включая классификацию, индексацию, оцифровку и т. д. В платформу входит также модуль отчетности, позволяющий просто и эффективно проводить анализ текущего состояния безопасности хранения и перемещения информации, а также строить сложные выборки по регрессивному и прогрессивному анализу.
В Symantec DLP используются два механизма, с помощью которых служба информационной безопасности может классифицировать данные и относить их к определенным группам важности. Первый, контентная фильтрация, - это возможность выделить в потоке передаваемой информации те документы или данные, которые содержат определенные слова, выражения, определенные типы файлов, а также определенные правилами сочетания букв и цифр (например, номер паспорта, кредитной карты и т. п.). Второй, метод цифровых отпечатков, позволяет защищать конкретные образы информации, блокируя попытки ее разбавления, использования фрагментов текста и т. д.