Утилита для редактирования контекстного меню виндовс. FileMenu Tools для тонкой настройки контекстного меню Windows Explorer
Когда мы нажимаем на Рабочем столе пр.кн.мыши то видим «убогое» и «невзрачное» контекстное меню .
Давайте контекстное меню сводим к стилисту и попробуем «подкрасить, напудрить, красиво одеть», короче внести хоть какие-то изменения в его мрачную и скучную жизнь 🙂 .

Наконец, подтвердите свой выбор кнопкой «Применить». В наших исследованиях мы часто сталкиваемся с недостатками данных, что особенно актуально для данных опроса. Бывают ситуации, когда пробелы в данных приносят ценную информацию. Например, количество недостающих данных в ответ на вопрос о симпатии к политическим партиям дает представление о количестве нерешительных людей, которым не нравится конкретная политическая группа. Небольшое количество пробелов в данных не является проблемой при статистическом анализе.
Однако большое количество из них может усомниться в надежности тестов. Стоит на ранней работе позаботиться о них как можно меньше. Конечно, лучше всего получить информацию о фактическом значении, которое должно быть записано вместо отсутствующих данных, но это не всегда возможно.
Способ для мозголомов
. Нажимаем сочетание клавиш Win+R
— пишем regedit
— нажимаем OK
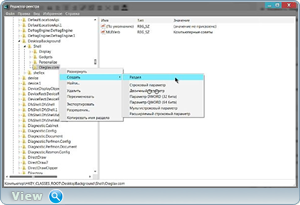
. Теперь нам нужен раздел HKEY_CLASSES_ROOT
. В редакторе реестра открываем следующую ветку:
HKEY_CLASSES_ROOT\DesktopBackground\Shell
. Кликаем на Shell
пр.кн.мыши — Создать
— Раздел
.. Щёлкаем два раза по параметру (По
умолчанию
) — В окне Значение
задаём имя Компьютерные советы.
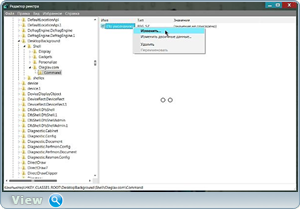
Теперь переходим в левую часть редактора реестра и там где мы создали новый раздел с названием сайта сайт нажимаем пр.кн.мыши — Создать
— Раздел
— пишем command
Способ оценки недостающих данных зависит в первую очередь от характера данных. Программа предложила несколько способов для устранения недостатков данных для отдельных переменных. Заполнение одного значения Выберите один из следующих вариантов, чтобы заменить отсутствующие значения одним и тем же значением в выбранном столбце: заданный пользователем, среднее арифметическое, рассчитанное по данным, геометрическое среднее, рассчитанное по данным, средняя гармоника, рассчитанная по данным, мода. Заполнение нескольких значений.
Выбрав один из приведенных ниже вариантов, замените отсутствующие значения в выбранном столбце на несколько значений. Эти значения могут быть предсказаны на основе столбца, для которого заполняются недостающие данные, но также могут быть предсказаны на основе значений других столбцов. Замените отсутствующие данные на значения.
На Рабочем столе нажимаем пр.кн.мыши по ярлыку браузера — Свойства — переходим в Объект : — копируем всё что находиться в поле объекта.

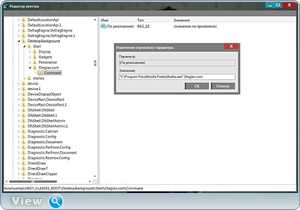
В разделе command нажимаем пр.кн.мыши (По умолчанию ) — Изменить…
Чтобы иметь возможность отличать данные, которые были вменены в фактические данные, замещенное место обозначается выбранным цветом. Пример. На этот раз мы рассмотрим таблицу, где имеются пробелы в данных о валовой прибыли для книжных продаж. В случае этих недостатков известны реальные значения, значения, полученные в программе для пробелов данных до фактических значений, могут быть получены для сравнения результатов, полученных различными методами. В этом примере мы будем использовать два способа замены отсутствующих данных: заменить на медианное значение и значение на основе модели регрессии.
В окне Значение: вставляем только что скопированный путь к браузеру и через пробел пишем сайт (или в адресной строке браузера копируем адрес любого сайта) после чего нажимаем ОК .
Другие возможности оставляют нас в покое. Замена отсутствующих данных на медианное значение выполняется на первом листе, называемом «Вставить медиану». В окне «Недостатки данных» добавьте переменную в качестве валовой прибыли и выберите метод замены в качестве медианного значения.
Мы подозреваем, что прибыль выше, когда они относятся к книгам известных авторов и более мелких, когда они относятся к тем неизвестным. Таким образом, мы рассчитываем среднюю валовую прибыль отдельно для книг известных и неизвестных авторов. Вычисление выполняется в листе данных «Вставить два медианы». Мы устанавливаем фильтр дважды для переменной, определяющей популярность автора - после получения значения 1, и как только Полученная медиана валовой прибыли в группе книг популярных авторов составляет около $ 51 тыс. А среди менее известных - около $ 34 тыс.
Ну вот осталось нажать пр.кн.мыши на рабочем столе и в контекстном меню будет виден новый пункт «Компьютерные советы «, нажав по нему вы прямиком выйдете на наш сайт (или любой другой, который вам больше всего нравиться).

Для добавления программ в меню, действия практически те же самые. В редакторе реестра открываем следующую ветку: HKEY_CLASSES_ROOT\Directory\Background\shell Кликаем пр.кн. мыши по папке shell и выбераем пункт Создать - Раздел и дайте ему какое-либо имя, в моем случае - Screen Translator . После этого, в правой части редакторе реестра дважды кликните по параметру (По умолчанию ) и впишите в поле Значение желаемое название программы. Далее, кликните пр.кн. мыши по созданному разделу (Screen Translator ) и опять выберите Создать - Раздел . Назовите раздел command после чего дважды кликните по параметру (По умолчанию ) и введите путь к программе, которую в дальнейшем будем запускать из контекстного меню Windows (обязательно в кавычках). Мой случай «C:\Program Files\Screen Translator\ScreenTranslator.exe»
Еще один способ заменить недостатки - использовать модель регрессии. Мы выбираем лист данных «Вставить из регрессии» и снова выбираем значение для валовой прибыли как переменной, которая должна быть добавлена в окне «Недостаток данных». Переменные, по которым мы будем прогнозировать валовую прибыль, будут больше на этот раз - это будут: издержки производства, расходы на рекламу и популярность автора. На этот раз результаты кажутся меньше фактического значения, к сожалению, для номера позиции нет результата.
Для этой книги у нас не было информации о стоимости производства, на которой мы хотели противостоять прогнозу. Преобразовать все переменные, содержащиеся в файле. Применение минимальной нормировки к интервалу; с использованием логарифмической нормировки; применение нормировки с коэффициентом; используя стандартизацию. Выборка является одним из способов генерации полиномиальных данных. Он присваивает указанное количество случаев каждой категории определенным образом. Сгенерированные данные возвращаются на новом листе.
Да ну их этих мозголомов 🙂 . Когда есть способ намного проще.

Способ для ленивых . Качаем утилиту от Kishan Bagaria, опытнейшего мастера по препарированию Windows. Ultimate Windows Context Menu Customizer умеет не только удалять и редактировать имеющиеся пункты контекстного меню, но и добавлять туда свои элементы. Кроме предложенных создателем утилиты пунктов, можно добавить и любые свои элементы, в том числе ссылки на программы, избранные папки и веб-страницы. Увы, утилита адаптированна только в Windows XP, Vista и 7. Кстати, а вот и видео о том как легко работать в этой чудо-программе.
Генерация может быть повторена так, чтобы лист генерировал большое количество сгенерированных столбцов в зависимости от количества повторений операции, установленной в окне образца. Для выбора этой опции требуется категория с более высокой вероятностью или относительным риском. Информация об определенной вероятности или относительном риске для каждой категории должна быть введена в выбранный столбец листа перед анализом. Вероятность должна определяться как значение от 0 до 1, где сумма вероятностей, данных для всех категорий, должна быть.