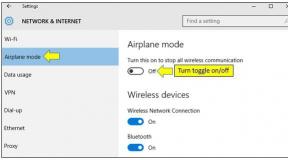
Protocolul UDP. Principiul de funcționare
Introducere
UDP este un protocol simplu, orientat pe datagramă strat de transport: Procesul emite o datagramă UDP la un moment dat, rezultând o datagramă IP care este transmisă. Acest lucru este în contrast cu protocoalele orientate spre flux, cum ar fi TCP, în care cantitatea de date care este scoasă de aplicație nu are practic nicio relație cu numărul de datagrame IP trimise.
Figura 11.1 prezintă încapsularea unei datagrame UDP într-o datagramă IP.
Figura 11.1 Încapsularea UDP.
Specificația UDP oficială este dată în RFC 768 [Postel 1980].
UDP este un protocol nesigur: trimite datagrame pe care o aplicație le scrie la nivelul IP, dar nu există nicio garanție că vor ajunge la destinația finală. Din punct de vedere al fiabilității, ați putea fi tentat să evitați utilizarea UDP și să utilizați întotdeauna protocoale de încredere, cum ar fi TCP. După ce TCP este tratat în , vom reveni la acest subiect și vom analiza ce tipuri de aplicații pot folosi UDP.
Aplicațiile nu trebuie să-și facă griji cu privire la dimensiunea datagramei IP rezultate. Dacă este mai mare ca dimensiune decât MTU pentru o anumită rețea (vezi Capitolul 2, secțiunea), datagrama IP va fi fragmentată. Acest lucru se aplică fiecărei rețele prin care va trece o datagramă în drumul său de la sursă la destinație, cu excepția primei rețele la care este conectată gazda care trimite. (Am definit conceptul de MTU de transport într-o secțiune din Capitolul 2.) Fragmentarea IP va fi discutată mai detaliat într-o secțiune a acestui capitol.
Antet UDP
Figura 11.2 prezintă câmpurile prezente în antetul UDP.

Figura 11.2 Antet UDP.
Numerele portului indică procesele de trimitere și primire. Arată că TCP și UDP folosesc numărul portului de destinație pentru a demultiplexa datele care provin de la IP. Deoarece IP demultiplexează datagramele IP de intrare pentru TCP și UDP (folosind valoarea protocolului din antetul IP), TCP se uită la numerele de porturi TCP, iar UDP se uită la numerele de porturi UDP. Numerele de port TCP sunt independente de numerele de port UDP.
În ciuda acestei independențe, dacă un serviciu rezervat este furnizat atât de TCP, cât și de UDP, același număr de port este de obicei ales pentru ambele straturi de transport. Acest lucru se face pentru comoditate și nu ca o cerință de protocol.
Câmpul de lungime UDP conține lungimea în octeți a antetului UDP și a datelor UDP. Valoarea minimă pentru acest câmp este de 8 octeți. (Nimic rău nu se va întâmpla dacă este trimisă o datagramă UDP cu lungime de date zero.) Parametrul de lungime UDP este redundant. O datagramă IP conține lungimea sa totală în octeți, astfel încât lungimea unei datagrame UDP este lungimea totală minus lungimea antetului IP (care este specificată în câmpul lungime antet de pe ).
Sumă de control UDP
Suma de verificare UDP acoperă antetul UDP și datele UDP. Amintiți-vă că suma de control din antetul IP acoperă doar antetul IP - nu acoperă datele conținute în datagrama IP. Atât UDP, cât și TCP conțin sume de control în anteturile lor, care acoperă atât antetul, cât și datele. Pentru UDP, suma de control este opțională, dar pentru TCP este necesară.
Suma de control UDP este calculată exact în același mod ca (Capitolul 3, secțiunea) suma de control pentru antetul IP (suma cuvintelor de 16 biți cu depășire), deși există diferențe. În primul rând, o datagramă UDP poate consta dintr-un număr impar de octeți, în timp ce se calculează suma de control Sunt adăugate cuvinte de 16 biți. Acest lucru adaugă zero octeți de completare la sfârșitul datagramei, dacă este necesar pentru a calcula suma de control. (octeții de completare nu sunt transmisi.)
În UDP și TCP, există pseudo-anteturi de 12 octeți (în datagramele UDP și segmentele TCP) numai în scopul calculării sumei de control. Pseudo-anteturile conțin anumite câmpuri din antetul IP. Toate acestea sunt făcute pentru a verifica dacă datele au ajuns la destinația dorită (IP-ul nu va accepta datagrame care nu sunt adresate acelei gazde și nu va putea transmite datagrame UDP destinate unui alt strat superior). Figura 11.3 prezintă pseudo-antetul și datagrama UDP.

Figura 11.3 Câmpurile utilizate pentru a calcula suma de control UDP.
În această figură, am arătat în mod specific o datagramă cu o lungime impară, caz în care este necesar un octet suplimentar pentru a calcula suma de control. Rețineți că lungimea datagramei UDP apare de două ori la calcularea sumei de control.
Dacă suma de control calculată este 0, aceasta este stocată ca toți biții (65535), aceste valori fiind echivalente în aritmetica unică-complement. Dacă suma de control transmisă este 0, înseamnă că expeditorul nu a calculat suma de control.
Dacă expeditorul calculează suma de control și destinatarul stabilește că există o eroare, datagrama UDP este distrusă în tăcere și nu este generat niciun mesaj de eroare. (Același lucru se întâmplă dacă stratul IP detectează o eroare în suma de verificare a antetului IP.)
Suma de control UDP este calculată de expeditor și verificată de destinatar. Vă permite să determinați orice modificări ale antetului UDP sau ale datelor care au avut loc de-a lungul căii dintre expeditor și destinatar.
Deși suma de control UDP este un parametru opțional, acesta trebuie întotdeauna calculat. La sfârșitul anilor 1980, unii producători de computere au început să dezactiveze calculul sumei de control UDP în mod implicit pentru a crește viteza sistemului de fișiere de rețea (NFS), care utilizează UDP. Acest lucru poate fi acceptabil într-unul retea locala, unde codul de redundanță ciclic este calculat pentru cadre la nivelul de legătură de date (cadre Ethernet sau Token Ring), care poate fi utilizat pentru a determina corupția cadrului atunci când datagrama trece prin routere. Credeți sau nu, există routere care au erori în software-ul sau hardware-ul lor care schimbă biți în datagramele pe care le direcționează. Aceste erori nu pot fi detectate în datagramele UDP dacă opțiunea sumă de control este dezactivată. De asemenea, trebuie remarcat faptul că unele protocoale de nivel de legătură (de exemplu, SLIP) nu au nicio formă de calcul a sumei de control pentru datele din legătură.
RFC privind cerințele gazdei necesită ca calculul sumei de control UDP să fie activat în mod implicit. De asemenea, solicită ca suma de control primită să fie verificată dacă a fost calculată de către expeditor (în cazul în care suma de control primită nu este zero). Unele implementări ignoră acest lucru și verifică suma de control primită dacă opțiunea de calculare a sumei de control de ieșire este activată.
Ieșirea comenzii tcpdump
Este destul de dificil de determinat dacă opțiunea de calcul al sumei de control UDP este activată pe un anumit sistem. De obicei, aplicația nu are acces la câmpul sumă de control al antetului UDP primit. Pentru a rezolva această problemă, autorul a adăugat o altă opțiune la programul tcpdump, după care a început să scoată sumele de control UDP primite. Dacă valoarea primită este 0, înseamnă că expeditorul nu a calculat suma de control.
Figura 11.4 arată ieșirea către și de la trei sisteme diferite din rețeaua noastră. Am rulat programul sock(), trimițând o singură datagramă UDP cu 9 octeți de date către un server echo standard.
>1 0.0 sun.1900 > gemini.echo: udp 9 (UDP cksum=6e90)
2 0.303755 (0.3038) gemini.echo > sun.1900: udp 9 (UDP cksum=0)
3 17.392480 (17.0887) sun.1904 > aix.echo: udp 9 (UDP cksum=6e3b)
4 17.614371 (0.2219) aix.echo > sun.1904: udp 9 (UDP cksum=6e3b)
5 32.092454 (14.4781) sun.1907 > solaris.echo: udp 9 (UDP cksum=6e74)
6 32.314378 (0.2219) solaris.echo > sun.1907: udp 9 (UDP cksum=6e74)
Figura 11.4 Ieșire de la tcpdump, care poate fi utilizată pentru a determina dacă opțiunea sumă de control UDP este activată pe o anumită gazdă.
De aici putem observa că două dintre cele trei sisteme au opțiunea sumă de control UDP activată.
De asemenea, rețineți că datagrama de ieșire are aceeași sumă de control ca datagrama de intrare (liniile 3 și 4, 5 și 6). În Figura 11.3, veți observa că cele două adrese IP sunt schimbate, la fel ca și cele două numere de port. Alte câmpuri din pseudo-antetul și antetul UDP au rămas aceleași, deoarece datele au fost repetate. Acest lucru confirmă faptul că suma de control UDP (și într-adevăr toate sumele de control din familia de protocoale TCP/IP) este o sumă simplă de 16 biți. Cu ajutorul acestuia, este imposibil să detectați o eroare, care constă în schimbarea locurilor a două valori de 16 biți.
Câteva statistici
[Mogul 1992] oferă câteva informații statistice despre apariția erorilor de sumă de control pe un server NFS destul de ocupat care rulează de 40 de zile. Figura 11.5 prezintă date statistice.
|
Numărul de erori în sumele de control |
Număr aproximativ de pachete |
|
| Ethernet | ||
| IP | ||
| UDP | ||
| TCP |
Figura 11.5 Statistica pachetelor corupte identificate folosind sumele de verificare.
Ultima coloană arată numărul aproximativ de pachete, deoarece alte protocoale utilizează stratul Ethernet și IP. De exemplu, nu toate cadrele Ethernet sunt utilizate de datagramele IP; Nu toate datagramele IP sunt folosite de UDP sau TCP, deoarece ICMP folosește și IP.
Rețineți că au fost detectate semnificativ mai multe erori de sumă de control TCP decât erori de sumă de control UDP. Acest lucru se datorează cel mai probabil faptului că TCP stabilește de obicei conexiuni „la distanță lungă” (care trec prin multe routere, poduri etc.), în timp ce traficul UDP este de obicei local.
Prin urmare, erorile enumerate în linia de jos nu sunt întotdeauna legate de stratul de legătură de date (Ethernet, Token ring). Când transferați date, ar trebui să activați întotdeauna opțiunea sumă de control la punctele finale. Cu toate acestea, dacă datele transmise sunt de o anumită valoare, nu ar trebui să aveți încredere totală în sumele de control UDP sau TCP, deoarece acestea sunt simple sume de control și nu sunt garantate pentru a proteja datele de toate erorile posibile.
Exemplu simplu
Vom folosi programul sock pentru a genera niște datagrame UDP, pe care le vom analiza folosind tcpdump:
>bsdi % sock -v -u -i -n4 svr4 arunca
conectat pe 140.252.13.35.1108 la 140.252.13.34.9
bsdi % sock -v -u -i -n4 -w0 svr4 arunca
conectat pe 140.252.13.35.1110 la 140.252.13.34.9
În primul caz de pornire a programului, modul de depanare este setat (-v), în timp ce puteți vizualiza numerele de porturi alocate dinamic, UDP este specificat (-u) în loc de TCP în mod implicit, iar modul sursă este setat, opțiunea ( -i), aceasta înseamnă că vom trimite date, mai degrabă decât să citim de la intrarea standard sau să scriem la ieșirea standard. Opțiunea -n4 îi spune să scoată 4 datagrame (în loc de valoarea implicită de 1024) către gazda destinație svr4. Serviciul de eliminare este descris în secțiunea din Capitolul 1. Folosim o dimensiune implicită de ieșire de 1024 de octeți per înregistrare.
A doua oară când am rulat programul, specificând -w0, aceasta va produce datagrame de lungime zero. Figura 11.6 arată rezultatul comenzii tcpdump pentru două exemple.
>1 0.0 bsdi.1108 > svr4.discard: udp 1024
2 0.002424 (0.0024) bsdi.1108 > svr4.discard: udp 1024
3 0.006210 (0.0038) bsdi.1108 > svr4.discard: udp 1024
4 0.010276 (0.0041) bsdi.1108 > svr4.discard: udp 1024
5 41.720114 (41.7098) bsdi.1110 > svr4.discard: udp 0
6 41.721072 (0.0010) bsdi.1110 > svr4.discard: udp 0
7 41.722094 (0.0010) bsdi.1110 > svr4.discard: udp 0
8 41.723070 (0.0010) bsdi.1110 > svr4.discard: udp 0
Figura 11.6 Ieșirea comenzii tcpdump atunci când datagramele UDP sunt trimise într-o singură direcție.
Ieșirea arată patru datagrame de 1024 de octeți urmate de patru datagrame de lungime zero. Fiecare datagramă urmează pe cea anterioară cu un interval de câteva milisecunde. (A durat 41 de secunde pentru a introduce a doua comandă.)
Înainte ca prima datagramă să fie trimisă, nu exista nicio legătură între expeditor și destinatar. (În discuția noastră despre TCP, arătăm că o conexiune trebuie stabilită înainte ca primul octet de date să fie trimis.) Este important de reținut că receptorul nu emite o confirmare când primește datele. Expeditorul, în acest exemplu, nu are idee dacă datele au fost primite la capătul de la distanță.
În cele din urmă, rețineți că numărul portului sursă UDP se modifică de fiecare dată când rulați programul. Portul a fost mai întâi 1108, apoi 1110. În secțiunea Capitolului 1, am arătat că numerele de porturi alocate dinamic utilizate de clienți variază de obicei între 1024 și 5000.
Fragmentarea IP
Figura 11.9 arată formatul de eroare inaccesibil ICMP pentru acest caz. Diferă de formatul afișat deoarece biții 16-31 din al doilea cuvânt de 32 de biți pot conține următorul hop MTU în loc să fie setați la 0.

Figura 11.9 Eroare de inaccesibil ICMP atunci când este necesară fragmentarea, dar bitul „nu fragmentare” este setat.
Dacă routerul dvs. nu acceptă acest lucru format nou Erori ICMP, următorul hop MTU este setat la 0.
Noul RFC privind cerințele routerului [Almquist 1993] specifică că un router trebuie să genereze acest nou formular atunci când emite un mesaj ICMP inaccesibil.
Problema pe care o vom discuta a apărut atunci când am primit o eroare ICMP în timp ce încercam să determinăm MTU-ul unei legături dial-up SLIP între routerul netb și soarele gazdă. Cunoaștem MTU-ul acestei legături de la sun la netb pentru că, în primul rând, acest lucru este specificat la configurarea SLIP pe gazda soare și, în al doilea rând, am văzut MTU-ul când am rulat comanda netstat în secțiunea din capitolul 3. Acum dorim să determina MTU în altă direcție. (Acest lucru explică modul de determinare a MTU folosind SNMP.) Pentru legăturile punct la punct, MTU nu trebuie să fie același în ambele direcții.
Pentru determinare a fost utilizată următoarea tehnică. Am rulat un ping de la gazda solaris la gazda bsdi, mărind dimensiunea pachetului de date până când fragmentarea a fost aplicată pachetelor. Procesul este prezentat în Figura 11.10.

Figura 11.10 Sisteme care au fost utilizate pentru a determina MTU a legăturii SLIP dintre netb și sun.
Programul tcpdump a fost lansat pe gazda solară, ceea ce ne-a permis să vedem cum se realizează fragmentarea în canalul SLIP. Fragmentarea nu a apărut și totul a fost în regulă până când dimensiunea datelor din pachetul ping a crescut de la 500 de octeți la 600. Solicitările ecou primite erau vizibile (ca și cum nu ar exista fragmentare), dar răspunsurile ecou au dispărut.
Pentru a înțelege mai bine ce se întâmplă, tcpdump a fost rulat și pe bsdi, după care a devenit clar ce se trimite și ce se primește. Figura 11.11 arată rezultatul.
>1 0.0 solaris >
2 0,000000 (0,0000) bsdi >
3 0,000000 (0,0000) soare >
trebuie să fragezi, mtu = 0 (DF)
4 0,738400 (0,7384) solaris > bsdi: icmp: cerere ecou (DF)
5 0,748800 (0,0104) bsdi > solaris: icmp: echo reply (DF)
6 0,748800 (0,0000) soare > bsdi: icmp: solaris inaccesibil -
trebuie să fragezi, mtu = 0 (DF)
Figura 11.11 Ieșirea programului tcpdump de la ping la bsdi de la Solaris cu o datagramă IP de 600 de octeți.
În primul rând, expresia (DF) de pe fiecare linie înseamnă că bitul „nu fragmentați” din antetul IP este setat la unu. Aceasta înseamnă că Solaris 2.2 setează în mod normal acest bit la unu ca parte a mecanismului de determinare a MTU de transport.
Linia 1 indică faptul că ping-ul trece prin netb la sun fără fragmentare și cu bitul DF setat, deci putem concluziona că dimensiunea critică MTU pentru netb gazdă SLIP nu a fost încă atinsă.
De asemenea, observați din rândul numărul 2 că flag-ul DF este copiat în fiecare răspuns ecou. Acesta este exact ceea ce a cauzat problema. Răspunsul ecou are aceeași dimensiune ca și cererea ecou (puțin peste 600 de octeți), dar MTU-ul interfeței SLIP de ieșire a gazdei sun este 552. Răspunsul ecou trebuie să fie fragmentat, dar steag-ul DF este setat. Acest lucru face ca sun să genereze o eroare ICMP inaccesabilă și să o trimită către bsdi (unde este distrusă).
Acesta este motivul pentru care nu am văzut ecouri de la Solaris. Răspunsurile nu treceau prin soare. Figura 11.12 arată calea pe care o parcurg pachetele.

Figura 11.12 Schimb de pachete pentru acest exemplu.
În cele din urmă, rețineți că expresia mtu=0 din liniile 3 și 6 din Figura 11.11 indică faptul că soarele nu returnează MTU pentru interfața de ieșire în mesajul ICMP inaccesibil, așa cum se arată în Figura 11.9. (În capitolul 25, vom rezolva această problemă folosind SNMP și ne vom asigura că SLIP MTU al interfeței netb este 1500.)
Determinarea MTU de transport folosind Traceroute
Deoarece majoritatea sistemelor nu acceptă funcția de determinare a MTU de transport, vom modifica programul traceroute() astfel încât să poată determina MTU de transport. Vom trimite un pachet cu bitul nu se fragmentează. Mărimea primului pachet trimis va fi egală cu MTU-ul interfeței de ieșire dimensiune. Dacă routerul care a trimis eroarea ICMP acceptă noua versiune, care include MTU-ul interfeței de ieșire în mesajul ICMP, folosim valoarea rezultată; altfel vom încerca următorul MTU mai mic. Deoarece RFC 1191 [Mogul și Deering 1990] afirmă că există un număr limitat de valori MTU, programul nostru are un tabel cu valori posibile și pur și simplu se va trece la următoarea valoare mai mică.
Să încercăm un algoritm similar de la soarele gazdă la alunecarea gazdei, știind că canalul SLIP are un MTU de 296:
>soare% traceroute.pmtu slip
MTU de ieșire = 1500
1 bsdi (140.252.13.35) 15 ms 6 ms 6 ms
2 bsdi (140.252.13.35) 6 ms
este necesară fragmentarea și DF setat, încercând un nou MTU = 1492
este necesară fragmentarea și DF setat, încercând un nou MTU = 1006
este necesară fragmentarea și DF setat, încercând un nou MTU = 576
este necesară fragmentarea și DF setat, încercând un nou MTU = 552
este necesară fragmentarea și DF setat, încercând un nou MTU = 544
este necesară fragmentarea și DF setat, încercând un nou MTU = 512
este necesară fragmentarea și DF setat, încercând un nou MTU = 508
este necesară fragmentarea și DF setat, încercând un nou MTU = 296
2 alunecare (140.252.13.65) 377 ms 377 ms 377 ms
În acest exemplu, routerul bsdi nu a returnat interfața de ieșire MTU în mesajul ICMP, așa că vom trece la următorul mai mic Valoarea MTU. Prima linie de ieșire pentru un TTL de 2 raportează numele de gazdă bsdi, dar acest lucru se datorează faptului că a fost returnat de router într-o eroare ICMP. Ultima linie de ieșire pentru un TTL de 2 este exact ceea ce ne așteptam.
Este ușor să modificați codul ICMP pe bsdi pentru a obține MTU-ul interfeței de ieșire. Și dacă facem asta și ne întoarcem la programul nostru, vom obține următoarea ieșire:
>soare% traceroute.pmtu slip
traceroute pentru a aluneca (140.252.13.65), 30 de hamei max
MTU de ieșire = 1500
1 bsdi (140.252.13.35) 53 ms 6 ms 6 ms
2 bsdi (140.252.13.35) 6 ms
este necesară fragmentarea și DF setat, următorul hop MTU = 296
2 alunecare (140.252.13.65) 377 ms 378 ms 377 ms
Nu are rost să treci prin opt aici. sensuri diferite MTU, routerul a raportat valoarea necesară.
Internetul mondial
O versiune modificată a traceroute a fost rulată de mai multe ori pe diferite gazde din întreaga lume. A ajuns în 15 țări (inclusiv în Antarctica), folosind diverse canale transatlantice și transpacific. Cu toate acestea, înainte de a face acest lucru, am mărit MTU-ul conexiunii SLIP dial-up dintre subrețeaua noastră și routerul netb (Figura 11.12) la 1500, la fel ca în Ethernet.
Din cele 18 ori în care a fost rulat programul, în doar două cazuri transportul MTU a fost mai mic de 1500. O legătură transatlantică avea un MTU de 572 (o valoare ciudată care nici măcar nu este listată în RFC 1191), iar routerul nu a returnat un Eroare ICMP pe noul format. O altă legătură între două routere din Japonia nu a procesat cadre de 1500 de octeți, iar routerul nu a returnat o eroare ICMP în noul format. După ce MTU a fost redus la 1006, totul a funcționat.
Concluzia pe care o putem trage din aceste experimente este că majoritatea (dar nu toate) rețelele de suprafață extinsă pot gestiona în prezent pachete mai mari de 512 octeți. Utilizarea caracteristicii de căutare MTU de transport permite aplicațiilor să funcționeze mult mai eficient folosind MTU-uri mai mari.
Determinarea MTU de transport la utilizarea UDP
Să ne uităm la interacțiunea dintre o aplicație care utilizează UDP și mecanismul de descoperire a transportului MTU. Trebuie să vedem ce se întâmplă atunci când o aplicație trimite o datagramă care este prea mare pentru un canal intermediar.
Deoarece singurul sistem care acceptă un mecanism de descoperire a transportului MTU este Solaris 2.x, îl folosim ca gazdă sursă pentru a trimite o datagramă de 650 de octeți pentru a slip. Deoarece gazda slip se află în spatele unei legături SLIP cu un MTU de 296, orice datagramă UDP mai mare de 268 de octeți (296 - 20 - 8) cu setul de biți „nu fragmentați” ar trebui să provoace o eroare ICMP „nu se poate fragmenta” din bsdi. router. Figura 11.13 prezintă topologia și MTU ale canalelor.

Figura 11.13 Sisteme utilizate pentru determinarea MTU de transport folosind UDP.
Următoarea comandă generează zece datagrame UDP de 650 de octeți la intervale de 5 secunde:
> solare % sock -u -i -n10 -w650 -p5 slip arunca
Figura 11.14 arată rezultatul comenzii tcpdump. Când a fost rulat acest exemplu, routerul bsdi a fost configurat să nu returneze MTU-ul următor hop ca parte a unei erori ICMP „nu se poate fragmenta”.
Prima datagramă trimisă cu setul de biți DF (linia 1) generează eroarea așteptată de la routerul bsdi (linia 2). Interesant este că următoarea datagramă, trimisă și cu setul de biți DF (linia 3), generează aceeași eroare ICMP (linia 4). Ne așteptam ca această datagramă să fie trimisă cu bitul DF dezactivat.
La linia 5, IP a realizat în cele din urmă că datagramele către această destinație nu ar trebui trimise cu biții DF setat și apoi a început să fragmenteze datagramele la gazda sursă. Acest comportament este diferit de ceea ce a fost arătat în exemplele anterioare, în care IP a trimis datagramele pe care le-a primit de la UDP, în timp ce routerelor cu MTU-uri mai mici (bsdi în acest caz) li s-a permis să se fragmenteze.
>1 0.0 solaris.38196 > slip.discard: udp 650 (DF)
2 0,004218 (0,0042) bsdi > solaris: icmp:
3 4.980528 (4.9763) solaris.38196 > slip.discard: udp 650 (DF)
4 4,984503 (0,0040) bsdi > solaris: icmp:
alunecare inaccesibil - trebuie să fragmentați, mtu = 0 (DF)
5 9.870407 (4.8859) solaris.38196 > slip.discard: udp 650 (frag 47942:552@0+)
6 9,960056 (0,0896) solaris > slip: (frag 47942:106@552)
7 14.940338 (4.9803) solaris.38196 > slip.discard: udp 650 (DF)
8 14,944466 (0,0041) bsdi > solaris: icmp:
alunecare inaccesibil - trebuie să fragmentați, mtu = 0 (DF)
9 19.890015 (4.9455) solaris.38196 > slip.discard: udp 650 (frag 47944:552@0+)
10 19,950463 (0,0604) solaris > slip: (frag 47944:106@552)
11 24.870401 (4.9199) solaris.38196 > slip.discard: udp 650 (frag 47945:552@0+)
12 24,960038 (0,0896) solaris > slip: (frag 47945:106@552)
13 29.880182 (4.9201) solaris.38196 > slip.discard: udp 650 (frag 47946:552@0+)
14 29,940498 (0,0603) solaris > slip: (frag 47946:106@552)
15 34.860607 (4.9201) solaris.38196 > slip.discard: udp 650 (frag 47947:552@0+)
16 34,950051 (0,0894) solaris > slip: (frag 47947:106@552)
17 39.870216 (4.9202) solaris.38196 > slip.discard: udp 650 (frag 47948:552@0+)
18 39,930443 (0,0602) solaris > slip: (frag 47948:106@552)
19 44.940485 (5.0100) solaris.38196 > slip.discard: udp 650 (DF)
20 44,944432 (0,0039) bsdi > solaris: icmp:
alunecare inaccesibil - trebuie să fragmentați, mtu = 0 (DF)
Figura 11.14 Determinarea MTU de transport folosind UDP.
Deoarece mesajul ICMP „nu se poate fragmenta” nu conține următorul hop MTU, aceasta înseamnă că IP a decis că toată lumea este mulțumită cu un MTU de 576. Primul fragment (linia 5) conține 544 de octeți de date UDP, 8 octeți de antet UDP și 20 de octeți de antet IP, dimensiunea totală a unei datagrame IP este de 572 de octeți. Al doilea fragment (linia 6) conține cei 106 octeți rămași de date UDP și antetul IP de 20 de octeți.
Din păcate, următoarea datagramă, linia 7, are bitul DF setat, deci este eliminată de bsdi și este returnată o eroare ICMP. Ce s-a întâmplat aici este că temporizatorul IP a expirat, care i-a spus IP să verifice dacă MTU-ul de transport a crescut cu reinstalare Bit DF. Vom vedea că acest lucru se întâmplă din nou în liniile 19 și 20. Comparând timpii din liniile 7 și 19 în care bitul DF este setat la unu, vedem că MTU de transport este verificat să crească la fiecare 30 de secunde.
Acest cronometru de 30 de secunde este prea scurt. RFC 1191 recomandă setarea temporizatorului la 10 minute. Valoarea temporizatorului poate fi modificată utilizând parametrul ip_ire_pathmtu_interval (Anexa E, secțiunea). În Solaris 2.2, nu există nicio modalitate de a dezactiva detectarea MTU de transport pentru o singură aplicație UDP sau pentru toate aplicațiile UDP. Poate fi activat sau dezactivat numai pentru întregul sistem prin modificarea parametrului ip_path_mtu_discovery. După cum putem vedea din acest exemplu, activarea caracteristicii de detectare a transportului MTU atunci când aplicațiile UDP trimit datagrame care probabil vor fi fragmentate va duce la eliminarea datagrama.
Dimensiunea maximă a datagramei acceptată de stratul IP pe solaris (576 de octeți) este incorectă. Am văzut în Figura 11.13 că MTU-ul real este de 296 de octeți. Aceasta înseamnă că fragmentele generate de solaris sunt fragmentate din nou pe bsdi. Figura 11.15 arată ieșirea tcpdump primită la gazda de destinație (slip) pentru prima datagramă care sosește (liniile 5 și 6 din Figura 11.14).
>1 0.0 solaris.38196 > slip.discard: udp 650 (frag 47942:272@0+)
2 0,304513 (0,3045) solaris > slip: (frag 47942:272@272+)
3 0,334651 (0,0301) solaris > slip: (frag 47942:8@544+)
4 0,466642 (0,1320) solaris > slip: (frag 47942:106@552)
Figura 11.15 Prima datagramă care ajunge la gazda slip de la Solaris.
În acest exemplu, gazda solaris nu ar trebui să fragmenteze datagramele de ieșire, ci ar trebui să dezactiveze bitul DF și să permită routerului cu MTU mai mic să efectueze fragmentarea.
Acum vom rula același exemplu, dar vom schimba comportamentul routerului bsdi, astfel încât să returneze următorul hop MTU în mesajul ICMP „nu se poate fragmenta”. Figura 11.16 prezintă primele șase linii de ieșire tcpdump.
>1 0.0 solaris.37974 > slip.discard: udp 650 (DF)
2 0,004199 (0,0042) bsdi > solaris: icmp:
3 4.950193 (4.9460) solaris.37974 > slip.discard: udp 650 (DF)
4 4,954325 (0,0041) bsdi > solaris: icmp:
alunecare inaccesibil - trebuie să fragmentați, mtu = 296 (DF)
5 9.779855 (4.8255) solaris.37974 > slip.discard: udp 650 (frag 35278:272@0+)
6 9,930018 (0,1502) solaris > slip: (frag 35278:272@272+)
7 9,990170 (0,0602) solaris > slip: (frag 35278:114@544)
Figura 11.16 Determinarea MTU de transport folosind UDP.
Încă o dată vedem că primele două datagrame au fost trimise cu bitul DF setat și ambele au primit erori ICMP. În prezent, eroarea ICMP indică următorul MTU înainte, care este 296.
În rândurile 5, 6 și 7, vedem că gazda sursă efectuează fragmentare, ca în Figura 11.14. Dacă MTU-ul următor hop este cunoscut, sunt generate doar trei fragmente, în comparație cu cele patru fragmente care sunt generate de routerul bsdi din Figura 11.15.
Interacțiunea dintre UDP și ARP
Folosind UDP, putem privi o interacțiune foarte interesantă între UDP și o implementare tipică ARP.
Folosim programul sock pentru a genera o datagramă UDP cu 8192 de octeți de date. Ne așteptăm ca în acest caz să fie generate șase fragmente Ethernet (vezi Capitolul 11). De asemenea, înainte de a rula programul, ne vom asigura că memoria cache ARP este goală, astfel încât înainte de trimiterea primului fragment, trebuie schimbată o cerere și un răspuns ARP.
>bsdi % arp -a verificați dacă memoria cache ARP este goală
bsdi % sock -u -i -n1 -w8192 svr4 aruncați
Ne așteptăm ca prima datagramă să provoace trimiterea unei cereri ARP. Următoarele cinci fragmente care sunt generate de IP pun două întrebări la care putem răspunde doar folosind tcpdump: vor fi gata fragmentele rămase să fie trimise înainte de a primi răspunsul ARP, dacă da, ce va face ARP cu aceste câteva pachete direcționate? la o anumită destinație în timp ce așteptați un răspuns ARP? Figura 11.17 arată rezultatul programului tcpdump.
>1 0.0 arp cine-are svr4 spune bsdi
2 0,001234 (0,0012) arp cine-are svr4 spune bsdi
3 0,001941 (0,0007) arp cine-are svr4 spune bsdi
4 0,002775 (0,0008) arp cine-are svr4 spune bsdi
5 0,003495 (0,0007) arp cine-are svr4 spune bsdi
6 0,004319 (0,0008) arp cine-are svr4 spune bsdi
7 0,008772 (0,0045) răspuns arp svr4 este la 0:0:c0:c2:9b:26
8 0,009911 (0,0011) răspuns arp svr4 este la 0:0:c0:c2:9b:26
9 0,011127 (0,0012) bsdi > svr4: (frag 10863:800@7400)
10 0,011255 (0,0001) răspuns arp svr4 este la 0:0:c0:c2:9b:26
11 0,012562 (0,0013) răspuns arp svr4 este la 0:0:c0:c2:9b:26
12 0,013458 (0,0009) răspuns arp svr4 este la 0:0:c0:c2:9b:26
13 0,014526 (0,0011) răspuns arp svr4 este la 0:0:c0:c2:9b:26
14 0,015583 (0,0011) răspuns arp svr4 este la 0:0:c0:c2:9b:26
Figura 11.17 Schimb de pachete la trimiterea unei datagrame UDP de 8192 de octeți prin Ethernet.
Această concluzie este destul de neașteptată. În primul rând, înainte de primirea primului răspuns ARP, sunt generate șase solicitări ARP. După cum ați putea ghici, IP generează rapid șase fragmente și este trimisă o solicitare ARP pentru fiecare.
Apoi, când este primit primul răspuns ARP (linia 7), este trimis doar ultimul fragment (linia 9)! Aceasta înseamnă că primele cinci fragmente au fost aruncate. În realitate, acesta este un exemplu de funcționare normală ARP. Majoritatea implementărilor rețin doar ultimul pachet care trebuie trimis către gazda destinație în timp ce așteaptă un răspuns ARP.
RFC privind cerințele gazdei necesită implementări pentru a preveni inundarea ARP (trimiterea în mod repetat a cererilor ARP pentru aceeași adresă IP cu frecvență înaltă). Frecvența maximă recomandată este o dată pe secundă. Aici vedem șase solicitări ARP în 4,3 milisecunde. RFC privind cerințele gazdei necesită ca ARP să stocheze cel puțin un pachet și trebuie să fie cel mai recent pachet. Este exact ceea ce am văzut aici.
Următoarea anomalie neexplicată este că svr4 a trimis înapoi șapte răspunsuri ARP, nu șase.
Un ultim lucru de remarcat este că tcpdump a rulat încă 5 minute după ce ultimul răspuns ARP a revenit, așteptând să vadă svr4 să trimită înapoi o eroare ICMP „timp depășit în timpul reasamblarii”. Mesajul ICMP nu a apărut niciodată. (Am arătat formatul acestui mesaj în . Câmpul de cod setat la 1 indică faptul că a trecut timpul în timp ce datagrama este reasamblată.)
Stratul IP trebuie să pornească un temporizator când apare primul fragment de datagramă. Aici, „primul” înseamnă primul fragment care sosește pentru o datagramă dată, nu doar primul fragment (cu un decalaj al fragmentului de 0). O valoare tipică de timeout variază între 30 și 60 de secunde. Dacă toate fragmentele pentru această datagramă nu au ajuns înainte de expirarea temporizatorului, toate fragmentele sunt aruncate. Dacă nu se face acest lucru, fragmentele care nu ajung niciodată (cum am văzut în acest exemplu) pot cauza depășirea tamponului de recepție.
Există două motive pentru care nu am văzut mesajul ICMP. În primul rând, majoritatea implementărilor Berkeley nu generează niciodată această eroare! Aceste implementări setează un cronometru și elimină toate fragmentele atunci când cronometrul expiră, dar nu este generată nicio eroare ICMP. În al doilea rând, primul fragment - fragmentul cu offset egal cu 0, care conține antetul UDP, nu a fost primit. (Acesta a fost primul dintre cele cinci pachete abandonate de ARP.) Implementarea nu este necesară pentru a genera o eroare ICMP dacă primul fragment nu este primit. Motivul este că receptorul de erori ICMP nu poate spune ce proces utilizator a trimis datagrama care a fost eliminată deoarece antetul stratului de transport nu era disponibil. Iar nivelul superior (fie o aplicație TCP, fie o aplicație UDP) va expira și va repeta transmisia.
În această secțiune, am folosit fragmentarea IP pentru a vedea cum funcționează comunicarea dintre UDP și ARP. Această interacțiune poate fi văzută dacă expeditorul trimite mai multe datagrame UDP în succesiune rapidă. Am folosit fragmentarea, deoarece pachetele sunt generate rapid folosind IP, ceea ce este mult mai rapid decât ca un utilizator să genereze mai multe pachete.
Dimensiunea maximă a datagramei UDP
Teoretic, dimensiunea maximă a unei datagrame IP poate fi de 65535 de octeți, care este limitată de câmpul de lungime completă de 16 biți din antetul IP (vezi). Cu o lungime a antetului IP de 20 de octeți și o lungime a antetului UDP de 8 octeți, datagrama UDP lasă un maxim de 65507 octeți pentru datele utilizatorului. Cu toate acestea, majoritatea implementărilor folosesc datagrame semnificativ mai mici.
Două restricții intră de obicei în joc. În primul rând, programul de aplicație poate fi limitat de interfața sa de programare. API-ul Sockets (Capitolul 1, secțiunea) oferă o funcție care poate fi apelată de o aplicație pentru a seta dimensiunea bufferelor de intrare și de ieșire. Pentru un socket UDP, această dimensiune este direct legată de dimensiunea maximă a unei datagrame UDP care poate fi citită și scrisă de UDP. În prezent, majoritatea sistemelor oferă o dimensiune maximă implicită a unei datagrame UDP care poate fi citită sau scrisă, care este de 8192 de octeți. (Această valoare este setată la 8192, deoarece acesta este ceea ce citește și scrie NFS în mod implicit.)
Următoarea limitare este determinată de implementarea nucleului TCP/IP. Pot exista caracteristici de implementare (sau erori) care limitează dimensiunea unei datagrame UDP la mai puțin de 65535 de octeți.
Autorul a experimentat cu diferite dimensiuni de datagramă UDP folosind programul sock. Folosind interfața loopback sub SunOS 4.1.3, dimensiunea maximă a datagramei UDP a fost de 32767 octeți. Nu a fost posibilă utilizarea unei valori mai mari. La transferul prin Ethernet de la BSD/386 la SunOS 4.1.3, dimensiunea maximă a unei datagrame IP pe care Sun a putut-o accepta era de 32786 (cu 32758 de octeți de date utilizator). Folosind interfața loopback din Solaris 2.2, dimensiunea maximă a unei datagrame IP care putea fi trimisă și primită a fost de 65535 octeți. La transferul de la Solaris 2.2 la AIX 3.2.2, a fost posibil să se transfere o datagramă IP cu o dimensiune maximă de 65535 octeți.
Trunchierea datagramei
Doar pentru că IP poate trimite și primi datagrame de o anumită dimensiune nu înseamnă că aplicația care primește este pregătită să citească datagrame de acea dimensiune. API-ul UDP permite aplicațiilor să specifice numărul maxim de octeți care trebuie procesați la un moment dat. Ce se întâmplă dacă datagrama primită este mai mare decât datagrama pe care aplicația este dispusă să o accepte?
Din păcate, răspunsul depinde de interfața de programare și de implementare.
Versiunile tradiționale ale API-ului socket Berkeley trunchiază datagramele, eliminând orice date care nu se potrivesc. Dacă aplicația este notificată depinde de versiune. (4.3 BSD Reno și versiunile ulterioare pot notifica aplicația că o datagramă a fost trunchiată.) Socket-urile API sub SVR4 (inclusiv Solaris 2.x) nu trunchiază datagramele. Orice date care nu se potrivesc sunt citite secvenţial. Aplicația nu este notificată cu mai multe cicluri de citire și i se va trimite o singură datagramă UDP. API-urile TLI nu aruncă date. În schimb, este returnat un indicator care indică faptul că există mai multe date decât pot fi citite simultan, astfel încât aplicația începe să citească datagrama rămasă secvenţial.
Când discutăm despre TCP, vom vedea că acest protocol oferă aplicației fluxuri secvențiale de octeți fără nicio restricție. TCP furnizează aplicației orice dimensiune de date necesită aplicația - și nicio dată nu se pierde pe acea interfață.
Eroare de suprimare a sursei ICMP
Folosind UDP, puteți genera o eroare de stingere a sursei ICMP. Această eroare poate fi generată de un sistem (router sau gazdă) atunci când primește datagramele mai repede decât pot fi procesate acele datagrame. Rețineți expresia „poate fi”. Sistemul nu necesită suprimarea sursei de trimitere, chiar dacă tampoanele sunt pline și datagramele sunt aruncate.
Figura 11.18 arată formatul erorii de suprimare a sursei ICMP. Suntem într-o poziție ideală pentru a genera o eroare similară în rețeaua noastră de testare. Putem trimite datagrame de la bsdi la router sun prin Ethernet, iar aceste datagrame trebuie direcționate printr-un canal SLIP. Deoarece canalul SLIP este de aproximativ o mie de ori mai lent decât Ethernet, putem depăși cu ușurință tamponul. Următoarea comandă trimite datagrame de 100 de 1024 de octeți de la gazda bsdi prin router sun la solaris. Trimitem datagrame către serviciul standard de eliminare, unde vor fi ignorate:
>bsdi % sock -u -i -w1024 -n100 solaris arunca

Figura 11.18 Eroare de suprimare a sursei ICMP.
Figura 11.19 arată ieşirea tcpdump corespunzătoare acestei comenzi.
>1 0.0 bsdi.1403 > solaris.discard: udp 1024
26 de linii nu sunt afișate
27 0.10 (0.00) bsdi.1403 > solaris.discard: udp 1024
28 0,11 (0,01) soare > bsdi: icmp: stingere sursă
29 0.11 (0.00) bsdi.1403 > solaris.discard: udp 1024
30 0,11 (0,00) sun > bsdi: icmp: source quench
142 de linii nu sunt afișate
173 0,71 (0,06) bsdi.1403 > solaris.discard: udp 1024
174 0,71 (0,00) soare > bsdi: icmp: stingere sursă
Figura 11.19 Suprimarea sursei ICMP de la soarele routerului.
Am eliminat multe linii din această ieșire. Primele 26 de datagrame au fost primite fără erori: am afișat doar ieșirea pentru prima. Începând de la a 27-a datagramă, de fiecare dată când este trimisă o datagramă primim o eroare de suprimare a sursei. Au fost 26+(74x2)=174 linii de ieșire în total.
Din calculul nostru de lățime de bandă a liniei seriale din capitolul 2, putem vedea că ar dura mai mult de o secundă pentru a transmite o datagramă de 1024 de octeți la 9600 bps. (În exemplul nostru, acest lucru va dura mai mult deoarece datagrama de 20+8+1024 de octeți va fi fragmentată deoarece MTU-ul legăturii SLIP de la sun la netb este de 552 de octeți.) Cu toate acestea, din timpii prezentati în Figura 11.19, vedem că router sun a primit toate cele 100 de datagrame în mai puțin de o secundă înainte ca prima să fie trimisă pe canalul SLIP. Este clar că am folosit multe dintre tampoanele sale.
Deși RFC 1009 necesită ca un router să genereze erori de suprimare a sursei atunci când tampoanele sale devin pline, noul RFC privind cerințele routerului [Almquist 1993] modifică acest lucru și spune că un router nu trebuie să genereze erori de suprimare a sursei.
Următorul punct de observat în exemplu este că programul sock nu a primit niciodată notificări că sursa a fost suprimată sau, dacă a făcut-o, le-a ignorat. Acest lucru sugerează că implementările BSD ignoră în mod obișnuit mesajele de suprimare a sursei primite atunci când se utilizează protocolul UDP. (În cazul TCP, atunci când se primește o notificare, transmisia de date pe o conexiune pentru care este generată suprimarea sursei este încetinită. Vom discuta acest lucru în secțiunea Capitolului 21.) Problema este că procesul care a generat datele care, la rândul său, a cauzat sursa de suprimare poate să se fi finalizat deja când mesajul de suprimare a sursei este primit. Și într-adevăr, dacă folosim program de timp Pe Unix, pentru a estima cât timp rulează programul sock, constatăm că a rulat doar aproximativ 0,5 secunde. Totuși, am văzut în Figura 11.19 că unele mesaje de suprimare a sursei au fost primite la 0,71 secunde după ce prima datagramă a fost trimisă, adică după ce procesul a încetat să ruleze. Ce se întâmplă dacă programul nostru produce 100 de datagrame și iese. Nu toate cele 100 de datagrame vor fi trimise - unele dintre ele vor fi în coada de ieșire.
Acest exemplu demonstrează că UDP este un protocol nesigur și arată importanța controlului fluxului. Chiar dacă programul de șosete a trimis cu succes 100 de datagrame în rețea, doar 26 au ajuns la destinație. Cele 74 rămase au fost cel mai probabil aruncate de routerul intermediar. Dacă aplicația nu acceptă o anumită formă de notificări, expeditorul nu știe dacă destinatarul a acceptat datele.
Server UDP
Există mai multe caracteristici ale utilizării UDP care afectează proiectarea și implementarea serverului. Proiectarea și implementarea clienților este de obicei mai ușoară decât implementarea serverelor. Acesta este motivul pentru care vom discuta aici despre dezvoltarea serverului, mai degrabă decât dezvoltarea clientului. Serverele interacționează de obicei cu sistemul de operare și majoritatea serverelor necesită să existe o modalitate de a gestiona cererile de la mai mulți clienți în același timp.
De obicei, atunci când un client pornește, stabilește imediat o conexiune la un server. Serverele, pe de altă parte, pornesc și apoi intră în somn în timp ce așteaptă să sosească o solicitare de la un client. În cazul UDP, serverul „se trezește” atunci când o datagramă sosește de la client, această datagramă poate conține o solicitare într-o anumită formă.
Nu vom lua în considerare aspectele de programare ale clienților și serverelor (el descrie totul mai detaliat), dar vom lua în considerare caracteristicile protocolului UDP care afectează proiectarea și implementarea unui server care utilizează UDP. (Vom discuta detaliile serverului TCP într-o secțiune din Capitolul 18.) Vom discuta câteva caracteristici în funcție de implementările UDP care vor fi utilizate și ne vom uita, de asemenea, la caracteristicile care sunt comune majorității implementărilor.
Adresa IP și numărul portului clientului
O datagramă UDP sosește de la client. Antetul IP conține adresele IP sursă și destinație, iar antetul UDP conține numerele portului UDP sursă și destinație. Când o aplicație primește o datagramă UDP, sistemul de operare trebuie să îi spună cine a trimis mesajul - adresa IP sursă și numărul portului.
Această caracteristică permite unui server UDP să gestioneze mai mulți clienți. Fiecare răspuns este trimis clientului care a trimis cererea.
Adresă IP de destinație
Unele aplicații trebuie să știe cui este destinată datagrama, adică adresa IP de destinație. De exemplu, RFC privind cerințele gazdei specifică faptul că un server TFTP trebuie să ignore datagramele primite care sunt trimise la o adresă de difuzare. (Vom descrie adresarea difuzării în , iar TFTP în .)
Aceasta înseamnă că sistemul de operare trebuie să transmită adresa IP de destinație din datagrama UDP primită către aplicație. Din păcate, nu toate implementările oferă această caracteristică.
API-ul sockets oferă această capacitate folosind opțiunea IP_RECVDSTADDR. Dintre sistemele acoperite în text, numai BSD/386, 4.4BSD și AIX 3.2.2 acceptă această opțiune. SVR4, SunOS 4.x și Solaris 2.x nu sunt acceptate.
Coada de intrare UDP
În secțiunea Capitolului 1, am spus că majoritatea serverelor UDP pot servi toate cererile către clienți folosind un singur port UDP (porturi de server precunoscute).
De obicei, dimensiunea cozii de intrare asociată fiecărui port UDP care este utilizat de aplicație este limitată. Aceasta înseamnă că cererile care sosesc în același timp de la clienți diferiți sunt puse automat într-o coadă UDP. Datagramele UDP primite sunt trimise aplicației (când solicită următoarea datagramă) în ordinea în care au fost primite.
Cu toate acestea, există posibilitatea, dacă coada este plină, ca modulul UDP din nucleu să elimine datagramele primite. Putem observa acest lucru cu următorul experiment. Începem programul nostru de șosete pe gazda bsdi, pornind astfel serverul UDP:
>bsdi % ciorap -s -u -v -E -R256 -r256 -P30 6666
de la 140.252.13.33, la 140.252.13.63: 1111111111 de la soare la adresa de difuzare
de la 140.252.13.34, la 140.252.13.35: 4444444444444 de la svr4 la adresa personala
Am folosit următoarele steaguri: -s, rulează programul ca server, -u pentru UDP, -v, tipărește adresa IP a clientului și -E imprimă adresa IP de destinație (în acest caz sistemul o permite). În plus, am setat tamponul de primire UDP pentru acest port la 256 de octeți (-R), împreună cu dimensiunea care poate fi citită de fiecare aplicație (-r). Indicatorul -P30 vă spune să așteptați 30 de secunde după ștergerea portului UDP înainte de a citi prima datagramă. Acest lucru ne oferă timp să pornim clienții pe alte două gazde, să trimitem niște datagrame și să vedem cum funcționează coada de primire.
După ce serverul a pornit și a trecut o pauză de 30 de secunde, pornim un client pe soarele gazdă și trimitem trei datagrame:
>soare% ciorap -u -v 140.252.13.63 6666 la adresa de difuzare Ethernet
conectat pe 140.252.13.33.1252 la 140.252.13.63.6666
1111111111
11 octeți de date (cu linie nouă)
222222222
10 octeți de date (cu linie nouă)
33333333333
12 octeți de date (cu linie nouă)
Adresa de destinație este adresa de difuzare (140.252.13.63). Apoi am pornit un alt client pe gazda svr4 și am trimis încă trei datagrame:
>svr4% ciorap -u -v bsdi 6666
conectat pe 0.0.0.0.1042 la 140.252.13.35.6666
4444444444444
14 octeți de date (cu linie nouă)
555555555555555
16 octeți de date (cu linie nouă)
66666666
9 octeți de date (cu linie nouă)
Primul lucru de observat în ieșirea interactivă afișată mai devreme pe bsdi este că numai două datagrame au fost primite de aplicație: prima de la sun, care a fost toate, și prima de la svr4, care a fost toate patru. Restul de patru datagrame au fost aruncate.
Ieșirea comenzii tcpdump din Figura 11.20 arată că toate cele șase datagrame au fost livrate gazdei de destinație. Datagrame de profit de la doi clienți în ordine inversă: mai întâi de la soare, apoi de la svr4 și așa mai departe. Putem observa, de asemenea, că toate cele șase au fost livrate în aproximativ 12 secunde, în perioada de 30 de secunde în timp ce serverul dormea.
>1 0.0 sun.1252 > 140.252.13.63.6666: udp 11
2 2.499184 (2.4992) svr4.1042 > bsdi.6666: udp 14
3 4.959166 (2.4600) sun.1252 > 140.252.13.63.6666: udp 10
4 7.607149 (2.6480) svr4.1042 > bsdi.6666: udp 16
5 10.079059 (2.4719) sun.1252 > 140.252.13.63.6666: udp 12
6 12.415943 (2.3369) svr4.1042 > bsdi.6666: udp 9
Figura 11.20 Ieșirea tcpdump pentru datagramele UDP trimise de doi clienți.
De asemenea, trebuie remarcat faptul că cu opțiunea -E, serverul poate afla adresa IP de destinație a fiecărei datagrame. Serverul poate alege ce să facă cu prima datagramă primită care a fost trimisă la adresa de difuzare.
În acest exemplu, este necesar să acordați atenție altor caracteristici. În primul rând, aplicația nu a raportat când coada de intrare a fost plină. Datagramele UDP suplimentare au fost pur și simplu aruncate. De asemenea, vedem în ieșirea tcpdump că nimic nu a fost trimis înapoi către client pentru a-l informa că datagramele au fost aruncate. Nu a fost trimis nimic asemănător cu un mesaj de suprimare a sursei ICMP, absolut nimic. În cele din urmă, dorim să subliniem că coada de intrare UDP operează pe o bază FIFO (primul intrat, primul ieşit), în timp ce, după cum am văzut în secţiunea acestui capitol, coada de intrare ARP operează pe un LIFO (ultimul în, primul ieşit). primul ieşit) bază.
Limitarea adresei IP locale
Majoritatea serverelor UDP folosesc metacaractere pentru adresele lor IP atunci când creează puncte finale UDP. Aceasta înseamnă că o datagramă UDP de intrare destinată portului serverului va fi acceptată de orice interfață locală. De exemplu, putem porni un server UDP pe portul 7777:
>soare % ciorap -u -s 7777
Vom folosi apoi comanda netstat pentru a vedea starea acestui punct final:
>soare% netstat -a -n -f inet
Conexiuni la internet active (inclusiv servere)
Proto Recv-Q Send-Q Adresă locală Adresă străină (stat)
udp 0 0 *.7777 *.*
În această ieșire, am eliminat multe linii și am lăsat doar pe cele care ne sunt interesante. Indicatorul -a raportează toate punctele finale ale rețelei. Indicatorul -n tipărește adresele IP în notație zecimală în loc să utilizeze DNS și să convertească adresele în nume și tipărește numere de porturi în loc de nume de servicii. Opțiunea -f inet raportează numai punctele finale TCP și UDP.
Adresa locală este tipărită ca *.7777, unde asteriscul înseamnă că orice adresă poate fi înlocuită ca adresă IP locală.
Când serverul își creează punctul final, poate specifica una dintre adresele IP locale ale gazdei, inclusiv una dintre adresele sale de difuzare, ca adresă IP locală a punctului final. În acest caz, datagrama UDP de intrare va fi transmisă la punctul final numai dacă adresa IP de destinație se potrivește cu adresa locală specificată. Folosind programul sock, puteți specifica o adresă IP înainte de numărul portului, iar această adresă IP devine adresa IP locală pentru punctul final. De exemplu,
>soare % ciorap -u -s 140.252.1.29 7777
din datagramele care sosesc pe interfața SLIP, selectează datagramele cu adresa 140.252.1.29. Ieșirea comenzii netstat va arăta astfel:
>
udp 0 0 140.252.1.29.7777 *.*
Dacă încercăm să trimitem o datagramă către acest server de la gazda bsdi, a cărei adresă este 140.252.13.35, prin Ethernet, va fi returnată o eroare ICMP despre indisponibilitatea portului. Serverul nu va vedea niciodată această datagramă. Figura 11.21 arată acest lucru mai detaliat.
>1 0.0 bsdi.1723 > sun.7777: udp 13
2 0,000822 (0,0008) sun > bsdi: icmp: sun udp port 7777 inaccessible
Figura 11.21 Eșec de procesare a datagramei UDP cauzată de o nepotrivire a adresei locale a serverului.
Este posibil să rulați alte servere pe același port, fiecare cu propria sa adresă IP locală. Cu toate acestea, aplicația trebuie să permită sistemului să refolosească același număr de port.
Opțiunea socket trebuie specificată în API-ul SO_REUSEADDR. Acest lucru este realizat de programul nostru de șosete folosind opțiunea -A.
Pe gazda sun putem porni cinci servere diferite pe același port UDP (8888):
>soare% ciorap -u -s 140.252.1.29 8888 pentru canalul SLIP
soare% ciorap -u -s -A 140.252.13.33 8888 pentru Ethernet
soare% ciorap -u -s -A 127.0.0.1 8888 pentru interfață loopback
soare% ciorap -u -s -A 140.252.13.63 8888 pentru cererile de transmisie Ethernet
soare% ciorap -u -s -A 8888 pentru orice altceva (metacaractere în adresa IP)
Primul dintre servere era de așteptat să fie pornit cu indicatorul -A, care spune sistemului că același număr de port poate fi reutilizat. Ieșirea comenzii netstat arată următoarele cinci servere:
>Proto Recv-Q Send-Q Adresă locală Adresă străină (stat)
udp 0 0 *.8888 *.*
udp 0 0 140.252.13.63.8888 *.*
udp 0 0 127.0.0.1 8888 *.*
udp 0 0 140.252.13.33 8888 *.*
udp 0 0 140.252.1.29 8888 *.*
În acest scenariu, numai datagramele destinate adresei 140.252.1.255 vor lovi serverul cu caractere wildcard folosite ca adresă IP locală, deoarece celelalte patru servere acoperă toate adresele posibile.
Când utilizați înlocuirea adresei IP, este utilizat un sistem de prioritate. Un punct final cu o adresă IP specificată care se potrivește cu adresa IP de destinație va fi întotdeauna ales înaintea unei adrese wildcard. Punctul final cu wildcard este utilizat numai atunci când nu se găsește nicio potrivire pentru adresa specificată.
Limitarea adreselor IP externe
În toate rezultatele comenzii netstat pe care le-am arătat mai devreme, adresele IP de la distanță și numerele de porturi la distanță sunt afișate ca *.*. Aceasta înseamnă că punctul final va accepta datagramele UDP primite de la orice adresă IP și orice număr de port. Majoritatea implementărilor permit punctelor finale UDP să restricționeze adresele de la distanță.
Cu alte cuvinte, punctul final poate accepta numai datagrame UDP de la adresa IP și numărul de port specificate. Programul nostru sock folosește opțiunea -f pentru a specifica adresa IP la distanță și numărul portului:
>soare % ciorap -u -s -f 140.252.13.35.4444 5555
În acest caz, adresa IP la distanță este setată la 140.252.13.35 (gazda noastră bsdi) și număr de la distanță portul la 4444. Portul de server precunoscut este 5555. Dacă rulăm netstat, vom vedea că este setată și adresa IP locală, chiar dacă nu am specificat-o direct:
>Proto Recv-Q Send-Q Adresă locală Adresă străină (stat)
udp 0 0 140.252.13.33.5555 140.252.13.35.4444
Acesta este un efect secundar al specificării unei adrese IP la distanță și a unui număr de port la distanță pe sistemele Berkeley: dacă nu a fost selectată o adresă IP locală la setarea adresei de la distanță, adresa locala este selectat automat. Adresa IP locală este setată la adresa IP a interfeței care este selectată utilizând rutarea IP pentru a ajunge la adresa IP de la distanță specificată. Într-adevăr, în acest exemplu, adresa IP a Sun pentru Ethernet-ul care este conectat la adresa de la distanță este 140.252.13.33.
Figura 11.22 prezintă cele trei tipuri de adrese și porturi pe care un server UDP le poate seta.
Figura 11.22 Specificarea adreselor IP locale și la distanță și a numărului de port pentru serverul UDP.
În toate cazurile, lport este portul precunoscut al serverului, iar localIP trebuie să fie adresa IP a interfeței locale. Ordinea în care sunt aranjate cele trei linii din Figura 11.22 arată ordinea în care modulul UDP încearcă să determine care punct final local a primit o datagramă. Cea mai restrictivă asociere adresa-port (prima linie) este selectată prima, iar cea mai puțin restrictivă (ultima linie, unde atât adresa IP, cât și numărul portului sunt specificate ca metacaractere) este selectată ultima.
Recepție multiplă per port
Deși nu sunt specificate în RFC, cele mai multe implementări permit ca o singură aplicație la un moment dat să fie asociată cu o adresă locală și un număr de port UDP. Când o datagramă UDP ajunge la gazda de destinație la adresa sa IP și numărul de port, o copie este livrată la un singur punct final. Adresa IP a punctului final poate fi reprezentată ca metacaractere, așa cum se arată mai devreme.
De exemplu, în SunOS 4.1.3 am pornit un server pe portul 9999 cu o adresă IP locală sub formă de wildcards:
>soare % ciorap -u -s 9999
Dacă încercăm apoi să pornim un alt server cu aceeași adresă wildcard locală și același port, nu va funcționa, chiar dacă specificăm opțiunea -A:
>soare% ciorap -u -s 9999 nu ar trebui să se întâmple așa
nu se poate lega adresa locală: adresă deja utilizată
soare% ciorap -u -s -A 9999 de aceea am specificat steagul -A
nu se poate lega adresa locală: adresă deja utilizată
Pentru sistemele care acceptă multicast (vezi), lucrurile stau diferit. Mai multe puncte finale pot folosi aceeași adresă locală și aceeași număr de port UDP, dar aplicația trebuie să spună API-ului că acest lucru este permis (steagul -A utilizează opțiunea socket SO_REUSEADDR).
4.4BSD, care acceptă multicasting, necesită ca aplicația să seteze o opțiune de socket diferită (SO_REUSEPORT) pentru a permite mai multor puncte finale să partajeze același port. Mai mult, fiecare punct final trebuie să specifice această opțiune, inclusiv primul punct final care utilizează acest port.
Când o datagramă UDP ajunge la adresa sa IP de destinație, care este o adresă de difuzare sau multicast și există mai multe puncte finale asociate cu acea adresă IP și numărul de port, o copie a datagramei de intrare este trimisă la fiecare punct final. (Adresa IP locală a punctului final poate fi specificată ca wildcards și se va potrivi cu orice adresă IP de destinație.) Cu toate acestea, dacă datagrama IP care sosește are o adresă IP de destinație care este o adresă privată, doar o copie a datagramei este livrată la un punct final. Care punct final primește datagrama adresei personale este dependent de implementare.
Concluzii scurte
UDP este un protocol simplu. Specificația oficială RFC 768 [Postel 1980] are doar trei pagini. Serviciile pe care le oferă proceselor utilizatorilor de deasupra și din spatele IP sunt numere de porturi și sume de verificare opționale. Am folosit UDP pentru a revizui calculele sumelor de control și a vedea cum funcționează fragmentarea.
Apoi ne-am uitat la eroarea ICMP de neatins, care face parte din noua caracteristică de determinare a MTU de transport (vezi Capitolul 2, secțiunea ). Ne-am uitat la determinarea MTU de transport folosind Traceroute și UDP. Se discută și procesul de interacțiune dintre UDP și ARP.
Am verificat că o eroare de suprimare a sursei ICMP poate fi trimisă de un sistem care primește datagrame IP mai repede decât poate procesa. Este posibil să generați cu ușurință aceste erori ICMP folosind UDP.
Exerciții
- În secțiunea acestui capitol, am provocat fragmentarea în Ethernet prin scrierea unei datagrame UDP cu o dimensiune a datelor utilizator de 1473 de octeți. Care este cea mai mică dimensiune a datelor utilizator care poate provoca fragmentarea pe Ethernet dacă se utilizează încapsularea IEEE 802 (Capitolul 2, secțiunea)?
- Citiți RFC 791 [Postel 1981a] și spuneți-mi de ce toate fragmentele, cu excepția ultimului, trebuie să aibă o lungime de un multiplu de 8 octeți.
- Imaginați-vă o datagramă Ethernet și UDP cu 8192 de octeți de date utilizator. Câte fragmente vor fi transferate și care va fi lungimea offset-ului pentru fiecare fragment?
- Continuând cu exemplul anterior, imaginați-vă că aceste datagrame sunt apoi transferate pe un canal SLIP cu un MTU de 552. Trebuie să vă amintiți că cantitatea de date din fiecare fragment (totul cu excepția antetului IP) trebuie să fie un multiplu de 8 octeți. Câte fragmente sunt transmise și care este decalajul și lungimea fiecărui fragment?
- O aplicație care utilizează UDP trimite o datagramă care este fragmentată în 4 părți. Imaginați-vă că fragmentele 1 și 2 au ajuns la destinație, în timp ce fragmentele 3 și 4 s-au pierdut. Aplicația expiră și apoi, după 10 secunde, retransmite datagrama UDP. Această datagramă este fragmentată exact în același mod ca prima transmisie (același offset și aceeași lungime). Acum imaginați-vă că fragmentele 1 și 2 se pierd, dar fragmentele 3 și 4 ajung la destinație. Temporizatorul de reasamblare de pe gazda receptor este setat la 60 de secunde, astfel încât, atunci când fragmentele 3 și 4 au ajuns la destinația lor finală, fragmentele 1 și 2 din prima transmisie nu fuseseră încă aruncate. Poate destinatarul să asambla o datagramă IP din aceste patru fragmente?
- De unde puteți ști că fragmentele din Figura 11.15 corespund de fapt rândurilor 5 și 6 din Figura 11.14? ), rutarea surselor hard și loose (Capitolul 8, secțiunea). Cum credeți că sunt gestionate aceste opțiuni în timpul fragmentării? Comparați răspunsul dvs. cu RFC 791.
- Am spus că datagramele IP primite sunt demultiplexate pe baza numărului portului UDP de destinație. Este corect?
APLICAȚII UDP
Protocolul UDP, printre multe alte aplicații, acceptă și Trivial File. Protocolul de transfer(TFTP), Simple Network Management Protocol (SNMP) și Routing Information Protocol (RIP).
TFTP (Typical File Transfer Protocol). Este folosit în principal pentru copierea și instalarea unui sistem de operare pe un computer de pe un server de fișiere,
TFTP. TFTP este o aplicație mai mică decât File Transfer Protocol (FTP). De obicei, TFTP este utilizat în rețele pentru un transfer simplu de fișiere. TFTP include propriul mecanism de control al erorilor și de numerotare a secvenței și, prin urmare, acest protocol nu necesită servicii suplimentare la nivelul de transport.
SNMP (Simple Network Management Protocol) monitorizează și gestionează rețelele și dispozitivele atașate acestora și colectează informații despre performanța rețelei. SNMP trimite mesaje PDU care permit software-ului de management al rețelei să monitorizeze dispozitivele din rețea.
RIP (Routing Information Protocol) este un protocol intern de rutare, ceea ce înseamnă că este utilizat în cadrul unei organizații, dar nu și pe Internet.
APLICAȚII TCP
Protocolul TCP, pe lângă multe alte aplicații, acceptă și Funcționează FTP, Telnet și Simple Mail Transfer Protocol (SMTP).
FTP (File Transfer Protocol) este o aplicație cu funcții complete care este utilizată pentru a copia fișiere folosind o aplicație client care rulează pe un computer conectat la o aplicație server FTP pe altul computer la distanță. Folosind această aplicație, fișierele pot fi primite și trimise.
Telnet vă permite să stabiliți sesiuni de terminal de la dispozitiv la distanță, de obicei cu gazdă UNIX, router sau comutator. Aceasta dă administrator de rețea capacitatea de a gestiona dispozitiv de rețea, de parcă s-ar afla în imediata apropiere, iar portul serial al computerului a fost folosit pentru control. Utilitatea Telnet este limitată la sistemele care utilizează sintaxa de comandă bazată pe caractere. Telnet nu acceptă controlul mediului grafic al utilizatorului.
SMTP (Protocol de transfer simplu e-mail) este un protocol de transfer de e-mail pentru Internet. Acceptă transferul de mesaje de e-mail între clienții de e-mail și serverele de e-mail.
PORTURI BINE CUNOSCUTE
Porturile binecunoscute sunt atribuite de IANA și variază de la 1023 și mai jos. Acestea sunt alocate aplicațiilor care sunt de bază pentru Internet.
PORTURI ÎNREGISTRATE
Porturile înregistrate sunt catalogate de IANA și variază de la 1024 la 49151. Aceste porturi sunt utilizate de aplicații licențiate, cum ar fi Lotus Mail.
PORTURI ASIGNATE DINAMIC
Porturile alocate dinamic sunt numerotate de la 49152 la 65535. Numerele acestor porturi sunt alocate dinamic pe durata unei anumite sesiuni.
Protocolul de datagramă utilizator - UDP
Protocolul UDP este unul dintre cele două protocoale de nivel de transport utilizate în stiva de protocoale TCP/IP. UDP permite unui program de aplicație să-și transmită mesajele printr-o rețea cu o suprasarcină minimă asociată cu conversia protocoalelor de nivel de aplicație în IP. Totuși, programul de aplicație însuși trebuie să aibă grijă să confirme că mesajul a fost livrat la destinație. Antetul (mesajului) datagramei UDP arată ca cel prezentat în Figura 2.10.
Orez. 2.10. Structura antetului mesajului UDP
Unitatea de date a protocolului UDP se numește pachet UDP sau datagramă utilizator. Un pachet UDP constă dintr-un antet și un câmp de date care conține pachetul stratului de aplicație. Antetul are un format simplu și este format din patru câmpuri de doi octeți:
Port sursă UDP - numărul portului procesului de trimitere,
Port destinație UDP - numărul portului procesului destinatar,
Lungimea mesajului UDP - lungimea pachetului UDP în octeți,
Suma de control UDP - suma de control a pachetului UDP
Nu toate câmpurile unui pachet UDP trebuie completate. Dacă datagrama trimisă nu așteaptă un răspuns, atunci pot fi plasate zerouri în locul adresei expeditorului. De asemenea, puteți refuza să calculați suma de control, dar vă rugăm să rețineți că protocolul IP calculează suma de control numai pentru antetul pachetului IP, ignorând câmpul de date
Porturile din antet definesc protocolul UDP ca un multiplexor care permite colectarea și trimiterea mesajelor din aplicații către nivelul de protocol. În acest caz, aplicația folosește un anumit port. Aplicațiile care comunică prin rețea pot utiliza porturi diferite, ceea ce se reflectă în antetul pachetului. În total, pot fi definite 216 porturi diferite. Primele 256 de porturi sunt alocate așa-numitelor „servicii binecunoscute”, care includ, de exemplu, portul UDP 53, care este atribuit serviciului DNS.
Domeniu Lungime determină lungimea totală a mesajului. Domeniu Sumă de control servește la controlul integrității datelor. O aplicație care utilizează protocolul UDP trebuie să aibă grijă de integritatea datelor analizând câmpurile Checksum și Length. În plus, la schimbul de date prin UDP, programul de aplicație însuși trebuie să se ocupe de monitorizarea livrării datelor către destinatar. Acest lucru se realizează de obicei prin schimbul de confirmări de livrare între programele de aplicație.
Cele mai cunoscute servicii bazate pe UDP sunt BIND Domain Name Service și NFS Distributed File System. Revenind la exemplul traceroute, acest program folosește și transportul UDP. De fapt, mesajul UDP este trimis în rețea, dar folosește un port care nu are serviciu, motiv pentru care este generat un pachet ICMP, care detectează lipsa serviciului pe mașina de recepție când pachetul ajunge în sfârșit la mașină de destinație.
Protocol de control al transferului - TCP
Dacă monitorizarea calității transmisiei de date prin rețea este importantă pentru o aplicație, atunci în acest caz se utilizează protocolul TCP. Acest protocol se mai numește și un protocol de încredere, orientat spre conexiune și orientat spre flux. Înainte de a discuta aceste proprietăți ale protocolului, să luăm în considerare formatul datagramei transmise prin rețea (Figura 2.11). Conform acestei structuri, TCP, ca și UDP, are porturi. Primele 256 de porturi sunt alocate WKS, porturile de la 256 la 1024 sunt alocate serviciilor Unix, iar restul pot fi folosite la discreția dvs. În câmp Numărul de secvență numărul pachetului este definit în secvența de pachete care alcătuiește întregul mesaj, urmat de un câmp de confirmare Numărul de cunoștințeși alte informații de control.

Orez. 2.11. Structura pachetelor TCP
Portul sursă (SOURS PORT) ocupă 2 octeți, identifică procesul de trimitere;
Portul de destinație (PORTUL DE DESTINARE) ocupă 2 octeți, identifică procesul destinatar;
Numărul de secvență (SEQUENCE NUMBER) ocupă 4 octeți, indică numărul de octeți, care determină offset-ul segmentului în raport cu fluxul de date trimise;
Numărul confirmat (NUMĂR DE CUNOAȘTERE) ocupă 4 octeți, conține numărul maxim de octeți din segmentul primit, mărit cu unu; această valoare este folosită ca chitanță;
Lungimea antetului (HLEN) este de 4 biți și indică lungimea antetului segmentului TCP, măsurată în cuvinte de 32 de biți. Lungimea antetului nu este fixă și poate varia în funcție de valorile setate în câmpul Opțiuni;
Reserve (RESERVED) ocupă 6 biți, câmpul este rezervat pentru utilizare ulterioară;
Biții de cod (CODE BITS) ocupă 6 biți și conțin informații de serviciu despre tipul unui anumit segment, specificate prin setarea biților corespunzători acestui câmp la unul:
URG - mesaj urgent;
ACK - chitanță pentru segmentul primit;
PSH - cerere de a trimite un mesaj fără a aștepta umplerea bufferului;
RST - cerere de restabilire a conexiunii;
SYN - mesaj folosit pentru sincronizarea contoarelor datelor transmise la stabilirea unei conexiuni;
FIN este un semn că partea de transmisie a atins ultimul octet din fluxul de date transmis.
O fereastră (WINDOW) ocupă 2 octeți, conține valoarea declarată a dimensiunii ferestrei în octeți;
Suma de control (CHECKSUM) are 2 octeți și este calculată pe segment;
Pointerul urgent (URGENT POINTER) ocupă 2 octeți, este utilizat împreună cu bitul codului URG, indică sfârșitul datelor care trebuie primite urgent, în ciuda depășirii bufferului;
OPȚIUNI - acest câmp are o lungime variabilă și poate lipsi cu totul, dimensiunea maximă a câmpului este de 3 octeți;
folosit pentru a rezolva probleme auxiliare, de exemplu, la alegerea dimensiunii maxime a segmentului;
PADDING, o umplutură cu lungime variabilă, este un câmp inactiv folosit pentru a aduce dimensiunea antetului la un număr întreg de cuvinte de 32 de biți. Fiabilitatea TCP constă în faptul că sursa de date repetă trimiterea, cu excepția cazului în care primește confirmarea de la destinatar într-o anumită perioadă de timp că a fost primită cu succes. Acest mecanism se numește Conștientizare pozitivă cu retransmisie (PAR)
. După cum am definit anterior, unitatea de transmisie (pachet de date, mesaj etc.) în termeni TCP se numește segment. Există un câmp de sumă de control în antetul TCP. Dacă datele sunt deteriorate în timpul transmisiei, atunci modulul care separă segmentele TCP de pachetele IP poate determina acest lucru folosind suma de control. Pachetul deteriorat este distrus și nimic nu este trimis la sursă. Dacă datele nu au fost corupte, acestea sunt transmise ansamblului de mesaje ale aplicației și o confirmare este trimisă sursei. Orientarea conexiunii este determinată de faptul că înainte de a trimite un segment de date, modulele TCP sursă și destinație fac schimb de informații de control. Acest schimb se numește strângere de mână
(literal „strângere de mână”). TCP folosește o strângere de mână în trei faze:
Sursa stabilește o conexiune cu destinația trimițându-i un pachet cu indicatorul Synchronize Sequence Numbers (SYN). Numărul din secvență identifică numărul pachetului din mesajul aplicației. Nu trebuie să fie 0 sau unu.
Dar toate celelalte numere îl vor folosi ca bază, ceea ce va permite colectarea pachetelor în ordinea corectă;
Destinatarul răspunde cu un număr în câmpul de confirmare a primirii SYN care se potrivește cu numărul setat de sursă. În plus, câmpul „număr în ordine” poate indica și numărul care a fost solicitat de sursă;

Sursa confirmă că a acceptat segmentul de destinație și trimite prima bucată de date.
După ce conexiunea este stabilită, sursa trimite date destinatarului și așteaptă confirmarea de la acesta că au fost primite, apoi trimite din nou datele etc., până când mesajul se termină. Mesajul se termină când bitul FIN este setat în câmpul steagurilor, ceea ce înseamnă „nu mai sunt date”.
Natura de streaming a protocolului este determinată de faptul că SYN determină numărul de pornire pentru numărarea octeților transmisi, nu a pachetelor. Aceasta înseamnă că dacă SYN a fost setat la 0 și s-au transmis 200 de octeți, atunci numărul setat în următorul pachet va fi 201, nu 2.
Este clar că natura de streaming a protocolului și cerința de a confirma primirea datelor dau naștere problemei vitezei de transfer al datelor. Pentru a rezolva această problemă, utilizați o „fereastră” - un câmp - fereastră. Ideea de a folosi fereastra este destul de simplă: transmiteți date fără a aștepta confirmarea primirii acestora. Aceasta înseamnă că sursa transmite o anumită cantitate de date egală cu fereastră fără a aștepta confirmarea primirii acesteia, iar după aceea oprește transmiterea și așteaptă confirmarea. Dacă primește confirmare doar pentru o parte din datele transmise, va începe să transmită o nouă porțiune din numărul care urmează celui confirmat. Acest lucru este prezentat grafic în Figura 2.13.

Orez. 2.13. Mecanismul de transmitere a datelor TCP
În acest exemplu, fereastra este setată la 250 de octeți. Aceasta înseamnă că segmentul curent este un segment cu un offset SYN de 250 de octeți. Cu toate acestea, după transmiterea întregii ferestre, modulul TCP sursă a primit o confirmare pentru a primi doar primii 100 de octeți. Prin urmare, transferul va începe de la 101 de octeți, și nu de la 251.
Astfel, am examinat toate proprietățile de bază ale protocolului TCP. Rămâne doar să numim cele mai cunoscute aplicații pe care TCP le folosește pentru schimbul de date. Acesta este în primul rând TELNET și FTP, precum și Protocolul HTTP care este inima În toată lumea Web.
Să întrerupem puțin conversația despre protocoale și să ne îndreptăm atenția către o componentă atât de importantă a întregului sistem TCP/IP precum adresele IP.
folosește UDP model simplu transferuri, fără strângeri implicite de mână pentru a asigura fiabilitatea, ordonarea sau integritatea datelor. Astfel, UDP oferă un serviciu nesigur, iar datagramele pot să apară neregulate, să fie duplicate sau să dispară fără urmă. UDP implică faptul că verificarea și corectarea erorilor fie nu sunt necesare, fie trebuie efectuate de aplicație. Aplicațiile sensibile la timp folosesc adesea UDP, deoarece este de preferat să aruncați pachetele decât să așteptați pachetele întârziate, ceea ce ar putea să nu fie posibil în sistemele în timp real. Dacă este necesară corectarea erorilor la nivelul interfeței de rețea, aplicația poate utiliza TCP sau SCTP concepute în acest scop.
Natura UDP ca protocol fără stat este, de asemenea, utilă pentru serverele care răspund la solicitări mici de la un număr mare de clienți, cum ar fi DNS și aplicații media de streaming precum IPTV, Voice over IP, protocoale de tunel IP și multe jocuri online.
Porturi de serviciu
UDP nu oferă nicio garanție de livrare a mesajelor protocolului de nivel superior și nu stochează starea mesajelor trimise. Din acest motiv, UDP este uneori numit Protocolul de datagramă nesigură.
Înainte ca suma de control să fie calculată, mesajul UDP este completat la sfârșit cu zero biți până la o lungime care este un multiplu de 16 biți (pseudo-antetul și biții zero suplimentari nu sunt trimise împreună cu mesajul). Câmpul sumă de control din antetul UDP în timpul calculării sumei de control trimis mesajele sunt acceptate ca nule.
Pentru a calcula suma de control, pseudo-antetul și mesajul UDP sunt împărțite în cuvinte (1 cuvânt = 2 octeți (octeți) = 16 biți). Apoi se calculează complementul pe biți al sumei tuturor cuvintelor cu complement pe biți. Rezultatul este scris în câmpul corespunzător din antetul UDP.
O valoare a sumei de control zero este rezervată și înseamnă că datagrama nu are o sumă de control. Dacă suma de control calculată este egală cu zero, câmpul este umplut cu unități binare.
La primirea unui mesaj, destinatarul calculează din nou suma de control (ținând cont de câmpul sumă de control), iar dacă rezultatul este număr binar de șaisprezece unii (adică 0xffff), atunci suma de control este considerată a converge. Dacă suma nu se adună (datele au fost corupte în timpul transmiterii), datagrama este distrusă.
Exemplu de calcul al sumei de control
De exemplu, să calculăm suma de control a mai multor cuvinte pe 16 biți: 0x398a, 0xf802, 0x14b2, 0xc281. Găsiți suma lor cu complement pe biți.
0x398a + 0xf802 = 0x1318c → 0x318d
0x318d + 0x14b2 = 0x0463f → 0x463f
0x463f + 0xc281 = 0x108c0 → 0x08c1
Acum găsim complementul pe biți a rezultatului rezultat:
0x08c1 = 0000 1000 1100 0001 → 1111 0111 0011 1110 = 0xf73e sau, în caz contrar - 0xffff − 0x08c1 = 0xf73e . Aceasta este suma de control dorită.
La calcularea sumei de control, se folosește din nou un pseudo-antet, simulând un antet IPv6 real:
| Biți | 0 – 7 | 8 – 15 | 16 – 23 | 24 – 31 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Adresa sursei | |||||||||||||||||||||||||||||||
| 32 | ||||||||||||||||||||||||||||||||
| 64 | ||||||||||||||||||||||||||||||||
| 96 | ||||||||||||||||||||||||||||||||
| 128 | Adresa destinatarului | |||||||||||||||||||||||||||||||
| 160 | ||||||||||||||||||||||||||||||||
| 192 | ||||||||||||||||||||||||||||||||
| 224 | ||||||||||||||||||||||||||||||||
| 256 | Lungimea UDP | |||||||||||||||||||||||||||||||
| 288 | Zerouri | Următorul titlu | ||||||||||||||||||||||||||||||
| 320 | Port sursă | Port de destinație | ||||||||||||||||||||||||||||||
| 352 | Lungime | Sumă de control | ||||||||||||||||||||||||||||||
| 384+ | Date |
|||||||||||||||||||||||||||||||
Adresa sursă este aceeași ca și în antetul IPv6. Adresa destinatarului - destinatar final; dacă pachetul IPv6 nu conține un antet de rutare, atunci aceasta va fi adresa de destinație din antetul IPv6, în caz contrar, pe nodul de pornire, va fi adresa ultimului element al antetului de rutare, iar pe nodul receptor, adresa de destinație din antetul IPv6-. Valoarea Next Header este egală cu valoarea protocolului - 17 pentru UDP. Lungimea UDP - lungimea antetului UDP și a datelor.
Fiabilitate și soluții pentru problemele de supraîncărcare
Datorită lipsei de fiabilitate, aplicațiile UDP trebuie să fie pregătite pentru anumite pierderi, erori și dublari. Unele dintre ele (de exemplu, TFTP) pot adăuga opțional mecanisme elementare de fiabilitate la nivel de aplicație.
Dar, de cele mai multe ori, astfel de mecanisme nu sunt folosite de aplicațiile UDP și chiar interferează cu ele. Streamingul media, jocurile multiplayer în timp real și VoIP sunt exemple de aplicații care folosesc adesea protocolul UDP. În aceste aplicații particulare, pierderea pachetelor nu este de obicei o problemă mare. Dacă aplicația necesită un nivel ridicat de fiabilitate, atunci pot fi utilizate un alt protocol (TCP) sau coduri de ștergere.
O problemă potențială mai mare este că, spre deosebire de TCP, aplicațiile bazate pe UDP nu au neapărat mecanisme bune de control și evitare a congestionării. Aplicațiile UDP sensibile la congestie care consumă o parte semnificativă din lățimea de bandă disponibilă pot compromite stabilitatea Internetului.
Mecanismele de rețea au fost concepute pentru a minimiza efectele potențiale ale congestiei în timpul sarcinilor necontrolate, de mare viteză. Elementele de rețea, cum ar fi routerele care folosesc cozi de pachete și tehnici de eliminare sunt adesea singurele instrumente disponibile pentru a încetini traficul excesiv UDP. DCCP (Datagram Congestion Control Protocol) este conceput ca o soluție parțială la această potențială problemă prin adăugarea de mecanisme la gazda finală pentru a monitoriza congestionarea fluxurilor UDP de mare viteză, cum ar fi media streaming.
Aplicații
Numeroase aplicații cheie de Internet utilizează UDP, inclusiv DNS (unde cererile trebuie să fie rapide și constau dintr-o singură cerere urmată de un singur pachet de răspuns), Protocolul simplu de gestionare a rețelei (SNMP), Protocolul de informații de rutare (RIP), Configurația dinamică a gazdei (DHCP) .
Traficul de voce și video este efectuat de obicei folosind UDP. Protocoalele de streaming video și audio în direct sunt concepute pentru a gestiona pierderile aleatorii de pachete, astfel încât calitatea să fie doar ușor degradată, în loc să provoace întârzieri mari atunci când pachetele pierdute sunt retransmise. Deoarece atât TCP, cât și UDP operează în aceeași rețea, multe companii au observat că recenta creștere a traficului UDP datorită acestor aplicații în timp real împiedică performanța aplicațiilor TCP precum bazele de date sau sistemele de contabilitate. Deoarece atât aplicațiile de afaceri, cât și aplicațiile în timp real sunt importante pentru companii, dezvoltarea de soluții de calitate la probleme este văzută de unii ca o prioritate de top.
Comparație între UDP și TCP
TCP este un protocol orientat spre conexiune, ceea ce înseamnă că este necesară o „strângere de mână” pentru a stabili o conexiune între două gazde. Odată stabilită conexiunea, utilizatorii pot trimite date în ambele direcții.
- Fiabilitate- TCP gestionează confirmarea mesajelor, retransmiterea și expirarea timpului. Se fac numeroase încercări de a transmite mesajul. Dacă se pierde pe parcurs, serverul va solicita din nou partea pierdută. Cu TCP nu lipsesc date sau (în cazul timeout-urilor multiple) conexiuni întrerupte.
- Ordine- Dacă două mesaje sunt trimise secvenţial, primul mesaj va ajunge mai întâi la aplicaţia destinatară. Dacă bucăți de date ajung în ordine greșită, TCP trimite datele nerespectate într-un buffer până când toate datele pot fi comandate și trimise aplicației.
- Greutatea- TCP necesită trei pachete pentru a stabili o conexiune socket înainte de a trimite date. TCP monitorizează fiabilitatea și congestia.
- Filetat- datele sunt citite ca un flux de octeți, nu sunt transmise desemnări speciale pentru limitele sau segmentele mesajelor.
UDP este un protocol mai simplu, bazat pe mesaje, fără conexiune. Aceste tipuri de protocoale nu stabilesc o conexiune dedicată între două gazde. Comunicarea se realizează prin transmiterea informațiilor într-o direcție de la o sursă la un destinatar fără a verifica gradul de pregătire sau starea destinatarului. Cu toate acestea, principalul avantaj al UDP față de TCP este în aplicații comunicare vocală prin Internet Protocol (Voice over IP, VoIP), în care orice „strângere de mână” ar împiedica o bună comunicare vocală. În VoIP, utilizatorii finali trebuie să ofere orice confirmare necesară de primire a mesajului în timp real.
- Nesigur- atunci când un mesaj este trimis, nu se știe dacă va ajunge la destinație - se poate pierde pe parcurs. Nu există concepte precum confirmare, retransmitere, expirare.
- Tulburare- dacă două mesaje sunt trimise aceluiași destinatar, atunci nu poate fi prevăzută ordinea în care ating scopul.
- Lejeritate- fără ordonarea mesajelor, fără urmărirea conexiunilor etc. Este un strat mic de transport proiectat în IP.
- Datagramele- pachetele sunt trimise individual și verificate pentru integritate doar dacă ajung. Pachetele au anumite limite care sunt respectate odată primite, ceea ce înseamnă că o operație de citire pe soclul de primire va produce mesajul așa cum a fost trimis inițial.
- Fără control de suprasarcină- UDP în sine nu evită aglomerația. Pentru aplicații cu dimensiuni mari debitului este posibil să provoace prăbușirea supraîncărcării dacă nu implementează controale la nivel de aplicație.
Link-uri RFC
- RFC 768 – Protocolul de datagramă utilizator
- RFC 2460 – Specificația protocolului Internet versiunea 6 (IPv6)
- RFC 2675 - Jumbograme IPv6
- RFC 4113 – Baza de informații de management pentru UDP
- RFC 5405 – Ghid de utilizare Unicast UDP pentru proiectanții de aplicații
Vezi de asemenea
Legături
- Kurose, J. F.; Ross, K. W. (2010). Rețele de calculatoare: o abordare de sus în jos (ed. a 5-a). Boston, MA: Pearson Education. ISBN 978-0-13-136548-3.
- Forouzan, B.A. (2000). TCP/IP: Protocol Suite, ed. 1. New Delhi, India: Tata McGraw-Hill Publishing Company Limited.
- [email protected]. „Prezentare generală a protocolului UDP”. IPv6.com. Preluat la 17 august 2011.
- Clark, M.P. (2003). Rețele de date IP și Internet, ed. I. West Sussex, Anglia: John Wiley & Sons Ltd.
- Postel, J. (august 1980). RFC 768: Protocolul de datagramă utilizator. Grupul operativ de inginerie a internetului. Preluat de la http://tools.ietf.org/html/rfc768
- Deering S. & Hinden R. (decembrie 1998). RFC 2460: Specificații Protocol Internet, versiunea 6 (IPv6). Grupul operativ de inginerie a internetului. Preluat de la http://tools.ietf.org/html/rfc2460
- „Impactul UDP asupra aplicațiilor de date”. networkperformancedaily.com. Preluat la 17 august 2011.
- D. Comer. Conectare la internet folosind TCP/IP. Capitolul 11. Protocolul UDP.
| Protocoale TCP/IP de bază după niveluri ale modelului OSI (Lista porturi TCP și UDP) | |
|---|---|
| Fizic | |
| Conductă | |
UDP (User Datagram Protocol) este un protocol de transport pentru transferul de date fără conexiune prin rețele IP. Este unul dintre cele mai simple protocoale de nivel de transport ale modelului OSI. ID-ul său IP este 0x11.
UDP este utilizat de obicei în aplicații precum streaming video și jocuri pe calculator, unde pierderea pachetelor este acceptabilă și reîncercarea este dificilă sau nejustificată, sau în aplicații cu răspuns la provocare (cum ar fi interogările DNS) în care crearea unei conexiuni necesită mai multe resurse decât retrimiterea. De fapt, funcțiile UDP se reduc la operațiuni de multiplexare și demultiplexare, precum și la simpla verificare a erorilor în date. Astfel, atunci când se utilizează U DP, aplicația comunică aproape direct cu protocolul de nivel de rețea IP.
UDP primește mesaje de la nivelul aplicației, adaugă câmpuri porturi sursă și destinație pentru demultiplexare de către receptor, precum și alte două câmpuri speciale și transmite segmentul rezultat la nivelul rețelei. Stratul de rețea împachetează segmentul într-o datagramă și îl transmite „dacă este posibil” către gazda destinație. Dacă acesta din urmă primește cu succes segmentul, UDP redirecționează datele segmentului către procesul dorit folosind câmpul numărul portului de destinație. Prin urmare, se spune că UDP realizează transfer de date fără conexiune.
Un exemplu de protocol de nivel de aplicație care utilizează servicii de protocol UDP este DNS. Când o aplicație DNS generează o interogare, creează un mesaj DNS și îl transmite protocolului UDP.
Comparația protocoalelor UDP și TCP.
Dacă o aplicație necesită confirmarea livrării mesajului, folosește protocolul TCP. TCP împarte mesajul în fragmente dimensiune mai mică, numite segmente. Aceste segmente sunt numerotate secvențial și trecute la protocolul IP, care apoi asamblează pachetele. TCP ține evidența numărului de segmente trimise către o anumită gazdă de către o anumită aplicație. Dacă expeditorul nu primește confirmarea în termen anumită perioadă timp, TCP consideră aceste segmente ca fiind pierdute și le retrimite. Numai porțiunea pierdută a mesajului este retrimise, nu întregul mesaj.
Protocolul TCP de la nodul receptor este responsabil pentru reasamblarea segmentelor de mesaj și transmiterea lor către aplicația corespunzătoare.
FTP și HTTP sunt exemple de aplicații care utilizează TCP pentru a furniza date.
Protocol UDP efectuează livrarea de date negarantată și nu solicită confirmare de la destinatar. UDP este protocolul preferat pentru streaming audio, video și voce prin Internet Protocol (VoIP). Confirmarea livrării nu va face decât să încetinească procesul de transfer al datelor, iar relivrarea nu este recomandabilă. Un exemplu de utilizare a protocolului UDP este radioul pe internet.
Protocolul ARP. Aplicație.
ARP(engleză) Protocolul de rezoluție a adresei- protocol de determinare a adresei) este un protocol de nivel scăzut utilizat în rețelele de calculatoare, conceput pentru a determina adresa stratului de legătură dintr-o adresă de nivel de rețea cunoscută. Acest protocol a devenit cel mai răspândit datorită ubicuității rețelelor IP construite pe Ethernet, deoarece în aproape 100% din cazuri ARP este utilizat cu această combinație. Descrierea protocolului a fost publicată în noiembrie 1982 în RFC 826. ARP a fost conceput pentru cazul transmiterii pachetelor IP pe un segment Ethernet. În același timp principiu general, propus pentru ARP, poate și a fost folosit pentru alte tipuri de rețele.
Există următoarele tipuri de mesaje ARP: cerere ARP și răspuns ARP. Sistemul expeditor folosește o cerere ARP pentru a solicita adresa fizică a sistemului receptor. Răspunsul (adresa fizică a gazdei de destinație) vine sub forma unui răspuns ARP.
Înainte de a transmite un pachet de nivel de rețea printr-un segment Ethernet, stiva de rețea verifică memoria cache ARP pentru a vedea dacă informațiile necesare despre gazda destinatarului sunt deja înregistrate în el. Dacă nu există o astfel de intrare în memoria cache ARP, atunci se face o solicitare de difuzare ARP. Această interogare pentru dispozitivele din rețea are următorul sens: „Știe cineva adresa fizică a dispozitivului care are următoarea adresă IP?” Când destinatarul cu această adresă IP primește acest pachet, va trebui să răspundă: „Da, aceasta este adresa mea IP. Adresa mea fizică este: …” Expeditorul își va actualiza apoi memoria cache ARP și va putea transmite informațiile destinatarului.
Intrările în cache ARP pot fi statice sau dinamice. Exemplul dat mai sus descrie o intrare dinamică în cache. De asemenea, puteți crea intrări statice în tabelul ARP.
ARP a fost dezvoltat inițial nu numai pentru protocolul IP, dar acum este folosit în principal pentru a mapa adrese IP și MAC.
Principiul de funcționare
Un nod care trebuie să mapeze o adresă IP la o adresă locală generează o solicitare ARP, o inserează într-un cadru de protocol de nivel de legătură, indicând o adresă IP cunoscută și difuzează cererea.
Toate gazdele din rețeaua locală primesc o solicitare ARP și compară adresa IP specificată acolo cu propria lor.
Dacă se potrivesc, nodul generează un răspuns ARP, în care își indică adresa IP și adresa locală și o trimite deja direcționată, deoarece în cererea ARP expeditorul indică adresa locală.